







© 2023, Минциева Аминат Ахметовна 146 2


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Была в сети 19.05.2024 22:53

Минциева Аминат Ахметовна
учитель информатики
Необратимые алгоритмы сжатия.
Категория:
Информатика
04.04.2023 22:17
Учебник:
Информатика (базовый и углубленный уровень), 11 класс, Гейн А. Г. и др. Изд. «Просвещение» 2019

Просмотр содержимого документа
«Необратимые алгоритмы сжатия.»
Урок 23
Необратимые алгоритмы сжатия.
Цели:
Образовательные: рассмотреть примеры решения задач на выполнения условия Фано; познакомить учащихся с принципами сжатия графической информации для экономии и надежности при хранении и передаче.
Развивающие: способствовать развитию познавательных интересов учащихся.
Воспитательные: воспитывать выдержку и терпение в работе, чувства товарищества и взаимопонимания.
Ход урока
1. Организационный момент.
2. Актуализация знаний.

3. Решение задач.
Задание 5 № 9185
Для кодирования некоторой последовательности, состоящей из букв И, К, Л, М, Н, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для буквы Н использовали кодовое слово 0, для буквы К – кодовое слово 10. Какова наименьшая возможная суммарная длина всех пяти кодовых слов?
Примечание. Условие Фано означает, что никакое кодовое слово не является началом другого кодового слова. Это обеспечивает возможность однозначной расшифровки закодированных сообщений.
Решение.
Нельзя использовать кодовые слова, которые начинаются с 0 или с 10. 11 также не можем использовать, поскольку тогда мы больше не сможем взять никакое другое кодовое слово, а нам их нужно пять. Поэтому берём трёхзначное 110. 111 опять же не можем использовать, потому что понадобиться ещё одно кодовое слово, а вместе с этим не останется больше свободных. Теперь осталось взять всего два слова и это будут 1110 и 1111. Итого имеем 0, 10, 110, 1110 и 1111 — 14 символов.
Ответ: 14.
Задание 5 № 9293
Для кодирования некоторой последовательности, состоящей из букв И, К, Л, М, Н, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для буквы Л использовали кодовое слово 1, для буквы М – кодовое слово 01. Какова наименьшая возможная суммарная длина всех пяти кодовых слов?
Примечание. Условие Фано означает, что никакое кодовое слово не является началом другого кодового слова. Это обеспечивает возможность однозначной расшифровки закодированных сообщений.
Решение.
Условие Фано — никакое кодовое слово не может быть началом другого кодового слова. Так как уже имеется кодовое слово 1, то никакое другое не может начинаться с 1. Только с 0. Также не может начинаться с 01, поскольку у нас уже есть 01. То есть любое новое кодовое слово будет начинаться с 00. Но это не может быть 00, так как иначе мы не сможем взять больше ни одного кодового слова, поскольку все более длинные слова начинаются либо с 1, либо с 00, либо с 01. Мы можем взять либо 000, либо 001. Но не оба сразу, поскольку опять же в таком случае мы больше не сможем взять ни одного нового кода. Тогда возьмём 001. И так как нам осталось всего два кода, то можем взять 0000 и 0001. Итого имеем: 1, 01, 001, 0000, 0001. Всего 14 символов.
Задание 5 № 15790
По каналу связи передаются сообщения, содержащие только семь букв: А, Б, Г, И, М, Р, Я. Для передачи используется двоичный код, удовлетворяющий условию Фано. Кодовые слова для некоторых букв известны: А — 010, Б — 011, Г — 100. Какое наименьшее количество двоичных знаков потребуется для кодирования слова МАГИЯ?
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Решение.
Следующую буква должна кодироваться как 11, поскольку 10 мы взять не можем. 100 взять не можем из-за Г, значит, следующая буква должна быть закодирована кодом 101. Следующая буква должна кодироваться как 000, поскольку 00 взять не можем, иначе не останется кодовых слов для оставшейся буквы, которые удовлетворяют условию Фано. Значит, последняя буква будет кодироваться как 001. Тогда наименьшее количество двоичных знаков, которые потребуются для кодирования слова МАГИЯ равно 2 + 3 + 3 + 3 + 3 = 14.
Ответ: 14.
Задание 5 № 15817
По каналу связи передаются сообщения, содержащие только семь букв: А, Б, Г, И, М, Р, Я. Для передачи используется двоичный код, удовлетворяющий условию Фано. Кодовые слова для некоторых букв известны: А — 010, Б — 00, Г — 101. Какое наименьшее количество двоичных знаков потребуется для кодирования слова МАГИЯ?
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Решение.
Следующую буква должна кодироваться как 011, поскольку 01 мы взять не можем, иначе код для буквы А не будет удовлетворять условию Фано. 10 из-за Г взять не можем, тогда следующая буква будет кодироваться как 100. Следующая буква должна кодироваться как 110, поскольку 11 взять не можем, иначе не останется кодовых слов для оставшейся буквы, которые удовлетворяют условию Фано. Значит, последняя буква будет кодироваться как 111. Тогда наименьшее количество двоичных знаков, которые потребуются для кодирования слова МАГИЯ равно
3 + 3 + 3 + 3 + 3 = 15.
Ответ: 15.
Задание 5 № 15915
По каналу связи передаются сообщения, содержащие только семь букв: А, Б, Г, И, М, Р, Я. Для передачи используется двоичный код, удовлетворяющий условию Фано. Кодовые слова для некоторых букв известны: А — 010, Б — 011, И — 10. Какое наименьшее количество двоичных знаков потребуется для кодирования слова ГРАММ?
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Решение.
Для трёх букв кодовые слова уже известны, осталось подобрать для оставшихся четырёх букв такие кодовые слова, которые обеспечат наименьшее количество двоичных знаков для кодирования слова ГРАММ.
Закодируем букву М кодовым словом 00, поскольку буква М повторяется в слове ГРАММ два раза. Для буквы Г возьмём кодовое слово 110. Кодовое слово 111 взять не можем, поскольку для остальных букв не останется кодовых слов, удовлетворяющих условию Фано. Оставшиеся две буквы закодируем кодовыми словами длины 4.
Таким образом, наименьшее количество двоичных знаков, которые потребуются для кодирования слова ГРАММ, равно 3 + 4 + 3 + 2 + 2 = 14.
Ответ: 14.
Задание 5 № 15942
По каналу связи передаются сообщения, содержащие только семь букв: А, Б, Г, И, М, Р, Я. Для передачи используется двоичный код, удовлетворяющий условию Фано. Кодовые слова для некоторых букв известны: А — 010, Б — 00, Г — 101. Какое наименьшее количество двоичных знаков потребуется для кодирования слова ГРАММ?
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Решение.
Для трёх букв кодовые слова уже известны, осталось подобрать для оставшихся четырёх букв такие кодовые слова, которые обеспечат наименьшее количество двоичных знаков для кодирования слова ГРАММ.
Закодируем букву М кодовым словом 11, поскольку буква М повторяется в слове ГРАММ два раза. Для буквы Р возьмём кодовое слово 011. Кодовое слово 100 взять не можем, поскольку для остальных букв не останется кодовых слов, удовлетворяющих условию Фано, поэтому оставшиеся две буквы закодируем кодовыми словами длины 4.
Таким образом, наименьшее количество двоичных знаков, которые потребуются для кодирования слова ГРАММ, равно 3 + 3 + 3 + 2 + 2 = 13
Ответ: 13.
Задание 5 № 16380
По каналу связи передаются сообщения, содержащие только семь букв: А, Б, И, К, Л, О, С. Для передачи используется двоичный код, удовлетворяющий условию Фано. Кодовые слова для некоторых букв известны: А — 001, И — 01, С — 10. Какое наименьшее количество двоичных знаков потребуется для кодирования слова КОЛОБОК?
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Решение.
Букву О закодируем кодовым словом 000, поскольку буква О повторяется в слове КОЛОБОК 3 раза. Букву К закодируем кодовым словом 110, поскольку буква К повторяется в слове КОЛОБОК 2 раза. Буквы Б и Л закодируем кодовыми словами 1110 и 1111 соответственно. Тогда наименьшее количество двоичных знаков, которые потребуются для кодирования слова КОЛОБОК равно 3 + 3 + 4 + 3 + 4 + 3 + 3 = 23.
Ответ: 23.
Задание 5 № 16434
По каналу связи передаются сообщения, содержащие только семь букв: А, Б, Г, И, Н, Р, Т. Для передачи используется двоичный код, удовлетворяющий условию Фано. Кодовые слова для некоторых букв известны: Г — 110, И — 01, Т — 10. Какое наименьшее количество двоичных знаков потребуется для кодирования слова БАРАБАН?
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Решение.
Букву А закодируем кодовым словом 000, поскольку буква А повторяется в слове БАРАБАН 3 раза. Букву Б закодируем кодовым словом 001, поскольку буква Б повторяется в слове БАРАБАН 2 раза. Буквы Р и Н закодируем кодовыми словами 1110 и 1111 соответственно. Тогда наименьшее количество двоичных знаков, которые потребуются для кодирования слова БАРАБАН равно 3 + 3 + 4 + 3 + 3 + 3 + 4 = 23.
Ответ: 23.
Изучение нового материала.
Алгоритмы сжатия данных, рассмотренные в лекции 1 (“Информатика” № 17/2007), обладали важным свойством — они сжимали данные так, что после декодирования исходное сообщение восстанавливалось в первоначальном виде. Такие алгоритмы называют обратимыми, или алгоритмами сжатия без потери информации. Однако такое буквальное воспроизведение исходной информации важно, как правило, лишь для текстовых сообщений. Если же речь идет о звуковой или видеоинформации, то при разработке алгоритмов сжатия можно учесть особенности человеческого восприятия звука и изображения.
Рассмотрим сначала методы сжатия графических данных. Одним из наиболее применяемых методов и фактически признанным сегодня стандартом сжатия является алгоритм, созданный Группой экспертов по фотоизображениям. Он получил название JPEG по первым буквам английского названия этой организации: Joint Photographic Experts Group.
Алгоритм JPEG основан на учете целого ряда особенностей зрительного аппарата человека. Во-первых, как мы уже рассказывали в учебнике 10-го класса, человеческое зрение обладает некоторой инерцией, т.е. изображение исчезает не мгновенно, а на некоторое время сохраняется. Именно этот эффект привел в свое время к созданию кинематографа. Именно этот эффект позволяет осуществлять дискретизацию изображения с последующей его оцифровкой. Во-вторых, чувствительность человеческого глаза к зеленому цвету почти в 4 раза выше, чем к красному, и почти в 10 раз выше, чем к синему. Значит, и для передачи информации о красной и синей составляющих можно использовать меньший объем памяти.
Само сжатие осуществляется алгоритмом JPEG в несколько этапов. Прежде всего производится перекодировка из RGB-модели в так называемую “YCbCr-модель”. В этой модели цвет представлен характеристиками: Y — яркость зеленого цвета, Cb — “цветоразность” зеленый–синий, Cr — “цветоразность” зеленый–красный (мы не даем точного определения понятию “цветоразность”, поскольку не планируем абсолютно точно описывать алгоритм JPEG, а интуитивное понимание этого слова есть, как мы надеемся, у каждого читателя). Затем в каждом втором столбце и в каждой второй строке таблицы пикселей, заполняющих экран, информация о Cb и Cr стирается. Иными словами, для каждого квадратика из четырех пикселей только в одном остается информация о цветоразностях (см. рис. 5).

Рис. 5. Сжатие по алгоритму JPEG
Это преобразование уменьшает объем данных в два раза: на каждые 4 пикселя вместо 12 значений передается только 6. После этого получившиеся числовые данные сжимаются еще и алгоритмом Хаффмана.
При декодировании непередаваемые характеристики цвета восстанавливаются так, чтобы у зрителя создавалось ощущение непрерывного изменения цвета. На рис. 6 схематично показано, информация о каких пикселях определяет значение непередаваемых характеристик при декодировании. Сначала приближенно восстанавливаются значения для пикселей, расположенных по диагонали от пикселей с полной цветовой информацией, а затем значения для остальных пикселей.
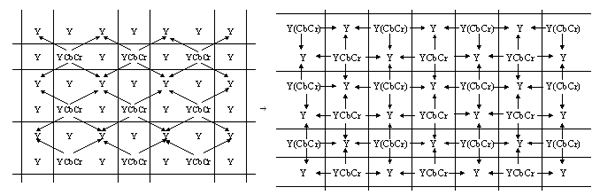
Рис.6. Схема восстановления характристик при декодировании
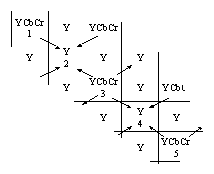

Рис. 7. График значений характеристики Cb вдоль ряда 1-2-3-4-5

Рис. 8. Сглаживание функции
Самый простой способ определения непередаваемых характеристик — вычисление среднего арифметического четырех известных значений. Однако если изобразить график изменения какой-либо восстанавливаемой характеристики (например, Cb) вдоль ряда пикселей с номерами 1, 2, 3, 4, 5, то вполне вероятно, что он в этом случае будет выглядеть так, как показано на рис. 7. Резкая смена направления в точке 3 изменения значений характеристики Cb вряд ли имела место в оригинале изображения. Математиками разработаны специальные методы, позволяющие, как говорят, сглаживать такие переходы (см. рис. 8). На математическом языке это означает, что функция, описывающая значения характеристики, не только непрерывна, но и дифференцируема, т.е. в каждой точке имеет производную. Для построения такой функции учитываются значения не только в четырех ближайших точках, но на гораздо более обширной области, а иногда и на всем множестве точек с известными значениями функции.
Впрочем, попытка учесть как можно больше точек вовсе не всегда эффективна. Такие функции получаются слишком громоздкими и сложными для вычислений. Математиками разработана теория так называемых “сплайнов”, которые позволяют гладко “склеивать” функции, определенные на небольшом множестве точек и легко вычисляемых.
Стандартизацией алгоритмов сжатия видеоданных занимается Группа экспертов по видеоизображениям — Motion Picture Experts Group. Поэтому алгоритмы, удовлетворяющие стандартам, принятым этой группой, принято называть общим именем MPEG. Среди них и алгоритм MPEG-1 Layer 3, более известный по своему сокращенному названию МР3. На самом деле этот алгоритм предназначен для сжатия аудиоинформации. Одним из параметров, регулирующих степень сжатия, является так называемый битрейт (от англ. bitrate) — количество бит, используемых для кодирования одной секунды звука.
Звук, как известно, — это колебательный процесс. Математики научились любое сложное колебание представлять в виде суммы простых колебаний, каждое из которых описывается амплитудой, частотой и фазой. Оказывается, что некоторыми составляющими можно просто пренебречь — даже самый музыкальный слух не уловит их отсутствие. Ответственность за то, какие составляющие и в каком количестве оставить, как раз и несет битрейт. Но даже при самом большом допустимом битрейте стандарта МР3 — 320 Кбит/с — данный алгоритм обеспечивает четырехкратное сжатие информации по сравнению с форматом Audio CD при том же субъективном восприятии качества звука. На заключительном этапе к полученным данным снова применяется алгоритм Хаффмана.
Алгоритмы сжатия собственно видеоинформации используют самые разнообразные подходы. Одним из базовых является метод опорного кадра. Дело в том, что при переходе от одного кадра к следующему нередко большая часть изображения остается неизменной. Если, к примеру, происходит встреча героев фильма в некоторой комнате, то ее обстановка, занимающая основную часть кадра, останется той же самой. Поэтому можно сохранять не целиком следующий кадр, а только изменения по сравнению с предыдущим кадром.
С другой стороны, если в кадре есть быстро сменяемые участки, то их можно кодировать с более низким качеством — человек привык к тому, что он не может рассмотреть детали быстро изменяющихся объектов. При этом статичное изображение и динамично меняющееся изображение можно отделить друг от друга и применять к ним разные алгоритмы сжатия. И только после декодирования их снова соединить в одно изображение.
Назовем имена нескольких алгоритмов из семейства MPEG.
MPEG-1 использовался в первых Video CD (VCD-I).
MPEG-2 используется в DVD и Super Video CD (SVCD, VCD-II).
MJPEG — формат сжатия видеоизображений, в котором каждый кадр сжимается по алгоритму JPEG.
MPEG-4 — один из самых эффективных форматов сжатия видео.
DivX, XviD — улучшенные модификации формата MPEG-4.
Вопросы и задания
1. Какой алгоритм сжатия данных называется обратимым?
2. В чем состоит отличие обратимых алгоритмов сжатия от необратимых?
3. Какие особенности человеческого зрения позволяют применять необратимые алгоритмы сжатия графических изображений без потери качества?
4. Пусть V0 — исходный объем данных, V — объем данных после обработки их сжимающим алгоритмом. Как, на ваш взгляд, обычно меняется отношение V0 / V при увеличении V0: возрастает, убывает или остается примерно одним и тем же?
Итоги урока.
Домашнее задание.
§ 19 стр. 88-91






Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!
Полезное для учителя

Реализация образовательных программ осуществляется с применением исключительно электронного обучения и ДОТ


