Россия, Ялта


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Был в сети 25.05.2024 22:13

Шаповалов Иосиф Леонидович
Учитель
Местоположение
Способы и автоматизация обработки авторских текстов
Категория:
Информатика
19.12.2023 00:28

Просмотр содержимого документа
«Способы и автоматизация обработки авторских текстов»
НАУЧНО-ИСЛЕДОВАТЕЛЬСКАЯ РАБОТА
НА ТЕМУ:
ИССЛЕДОВАНИЕ СПОСОБОВ И АВТОМАТИЗАЦИЯ ОБРАБОТКИ АВТОРСКИХ ТЕКСТОВ ДЛЯ ОПРЕДЕЛЕНИЯ ПСИХОТИПОВ
ВЫПОЛНИЛ:
Учитель математики и информатики
Шаповалов Иосиф Леонидович
Ялта, 2019
ВВЕДЕНИЕ
Настоящая работа посвящена исследованию взаимосвязи психологических и языковых характеристик личности, анализу психотипа (социотипа) человека как параметра его личности по лингвистическому критерию и проверке точности автоматического определения психотипа (социотипа) человека по его речевым характеристикам.
Как отмечал Карасик В.И. в своей работе «Языковой круг: личность, концепты, дискурс»: "лингвистическое изучение языковой личности базируется на тех психологических и социологических особенностях, которые находят выражение в языковой семантике и прагматике и позволяют построить типологию языковых личностей" [15]. Такое видение вопроса лишь подтверждает тот представление, что посредствам письма и речевого аппарата человек демонстрирует свои внутренние черты социальности, этических и моральных норм, видения и представление мира в целом [16].
Зная, что «язык» человека – это своего рода зеркало, отражающее его внутренний мир, мы применили для определения психологической принадлежности человека методы интеллектуального анализа данных (неструктурированных текстов). Результаты данной работы приведены в практической части данной работы. При подготовке к проведению данного исследования, необходимо было детально изучить и проанализировать основы психолингвистики и соционики.
Каким бы образом человек не пытался скрыть свои психические черты, он не способен постоянно контролировать выражение своих мыслей в написание, или устное выражении, что позволяет крайне качественно провести анализ его текстов и сделать соответствующие выводы и психических чертах их автора. Кроме того, существует прямая связь психологических аспектов личности с ее внешними проявлениями, это касается и языковых особенностей при написании текста. В частности, нас интересовала возможность автоматизации в выявлении взаимосвязи между психотипом человека и его лингвистическими особенностями при написании текста. Например, в” избранных психологических работах " А. Н. Леонтьев представляет наиболее распространенную точку зрения, согласно которой психическая функция восприятия ставится на первый план в характеристике сознания [13]. В своём фундаментальном труде “Психологические типы” К. Г. Юнг детально рассмотрел и заострил внимание на специфике восприятия человеком внешней информации, что, по его мнению, позволяет произвести его классификацию, учитывая личностные особенности психики любого человека [36]. Языковую типологию личности человека достаточно просто построить на основе проводимого лингвистического анализа её языковых характеристик. Что позволяет провести её типирование, основываясь на выделенных данных семантического ядра текста и анализа его языковых особенностей [17].
В последнее десятилетие областью обработки естественного языка стало NLP (Обработка естественного языка) и, в частности, его подраздел "интеллектуальный анализ данных" довольно интенсивно развивается в зарубежных странах [4]. Но, к сожалению, в России эти методы развиты недостаточно массово, что связано с отсутствием достаточного количества предложений на данный вид деятельности. Исключение составляет корпоративный и ИТ-кластеры.
Тем не менее, наблюдается постепенный рост активности в этой сфере со стороны различных сфер жизни. Современный мир остро нуждается в совершенствовании и разработке новых алгоритмов и методов обработки Больших данных. По результатам исследований [30] количество информации, накапливающееся на физических носителях, увеличивается вдвое ежегодно и данный процесс будет только ускоряться. До 70% из этих данных представляет собой неструктурированный массив текста на различных языках, требующий эффективной обработки и грамотного анализа. Современные же алгоритмы анализа в основе своей работы предполагают увеличение производительности за счёт повышения мощностей аппаратной части.
Как было отмечено выше, имея стремительный рост информации в неструктурированном виде - в форме естественного языка и, учитывая сложности при её обработке, налицо наличие проблемы анализа подобных массивов данных. Сегодня всё больше и больше сфер деятельности человека выражает нехватку инструментов аналитического разбора текстов. По данным аналитических исследований агентства IDC, к 2025 году предполагается увеличение объёма данных, накопленных человечеством, до 160 ЗБайт. И, как несложно догадаться, основой массива этой информации является информация в таких формах, как фотографии, видеозаписи, аудиозаписи, авторские текста на ЕЯ.
К задачам современных алгоритмов анализа неструктурированных данных помимо задачи классификации и кластеризации, следует отнести желание добычи из них полезной информации. Целью данной работы как раз и является совмещение этих двух целей, а именно: автоматическая классификация авторских текстов в соответствии с заданными критериями, на основании извлечённых из него закономерностей и характеристик.
Профилирование автора (классификация авторских текстов) – это задача отнесения автора исследуемого текста к заданной группе, на основании выявления значимых личностных характеристик человека. При решении подобного рода задач и автоматизации данного процесса, в большинстве случает прибегают к использованию методов на основе машинного обучения моделей классификаторов. Методика подобных моделей заключается в получении входного текста, а на выходе – получение некоторых сведений об авторе представленного текста, таких как: пол человека, возрастные характеристики, психологический образ, принадлежность к чему-либо или нечто другое.
Среди задачи профилирования авторов также выделяют такие подзадачи, как: сантимент-анализ (англ. Sentiment Analysis) и анализ высказываний (англ. Opinion Mining). Здесь одним из признаков психотипа личности, является его эмоциональная окраска. К примеру, если мы к переделённому психотипу автора применим критерий на основе эмоционального показателя то, можно наперёд определить его поведенческие характеристики, основываясь на эмоциональном состоянии на момент проведения исследования. Описанная методика применима в различных направлениях деятельности человека, например, возможно проведение аналитических исследований социальных групп, посетителей онлайн магазинов, настроений избирателей или работников предприятия, что позволяет проводить к примеру, направленных рекламные акции.
Проведение работ по выявлению семантического портрете пользователя. Анализа текстовой информации для её дальнейшей классификации по заданным правилам и др. требует создания новых качественных алгоритмов и современных подходов. По этой причине, учитывая необходимость человека в быстром поиске и получении информации из неструктурированного вида, крайне актуальной является анализ семантического преобразования подобных текстов. Преобразование представляется как процесс переработки текста, в результате которого будет получен семантически сходный (подобный) с оригинальным документом текстовый массив. Такой массив текста является близким по смыслу к оригиналу. Применяя к практической области возникает необходимость создания алгоритмов автоматического аннотирования, векторизации и многих иных видов исследования неструктурированных авторских массивов текстовой информации.
На сегодня подобные способы классификации авторских текстов с использованием средств автоматизации широко применяются в различных областях сферы деятельности человека.
Определение психотипа (социотипа) человека по написанному им неструктурированному тексту является крайне важной задачей и имеет хорошие перспективы применения в различных областях жизнедеятельности. Одним из ключевых факторов стабильной и прогрессирующей работы современного предприятия является наличие психологически устойчивого, слаженного коллектива работников. Выживание и экономическое состояние современного технологического предприятия напрямую зависит от подобного человеческого фактора. Подбор персонала по анкетам не всегда может дать качественный результат, что обусловлено различными факторами, такими как возбуждение, желание скрыть любую информацию, предать несуществующие черты характера. Кроме того, при массовом анализе с помощью анкет возникает большая нагрузка на аналитика. Гораздо более простым и незаметным способом извлечения информации о респонденте являются его высказывания, публикации, посты в социальных сетях. Существует огромное количество данных о людях в" чистом " виде. Не менее актуально и популярно определение типов личности потребителей при проведении масштабных маркетинговых исследований или рекламных кампаний. Своевременное выявление потребительских желаний и интересов даёт мощные преимущества перед кампаниями-конкурентами, приводит к улучшениям в планировании финансовой деятельности организации, лучшему сервису. Другая область-политическая борьба. Здесь огромную роль играет понимание особенности психики избирателя при проведении точечной агитации.
Как уже отмечалось выше, в Российской Федерации технология классификации и агрегирования данных о личности человека в массовом порядке практически не используется. На русском языке нет грамотных и понятных научных разработок для масс в области интеллектуального анализа данных. В связи с этим мы считаем, что работа в этом направлении является крайне перспективной и в будущем только станет более актуальным направлением экономического развития. Кроме того, тема исследования актуальна в связи с быстро растущей популярностью психологии в настоящее время. Современный человек начинает искать в себе ответы на многие вечные вопросы, а изучение мышления и его различных проявлений является одним из важных векторов современных научных интересов.
Актуальность заключается в решении проблемы типирования психотипов на основе больших объёмов данных, которая возникает на предприятиях при необходимости прогнозирования поведения сотрудников, клиентов, обучающихся и иных категорий людей.
Постановка проблемы.
В работе было установлено, что заинтересованные организации в своей деятельности при работе с человеческим ресурсом не применяют автоматизированные подходы, направленные на исследования психологических аспектов личности своих клиентов. В частности, акцентируется внимание на возможности использования методики интеллектуального анализа (Text Mining) неструктурированных авторских текстов в среде RapidMiner с целью определения психотипов их авторов.
Объектом исследования представленной работы являются авторские тексты (в виде постов в социальных сетях, анкет, резюме и др.) работников, студентов, пользователей социальных сетей, посетителей онлайн магазинов и иных категорий.
Предметом исследования являются модели и информационные технологии для определения психотипов авторов текстовых массивов.
Целью является исследование способов и автоматизация обработки авторских текстов для определения психотипов на основании анализа текстовых массивов.
Задачи исследования
Анализ и выбор классификации психотипов.
Исследование и выбор алгоритмов классификации данных для классификации психотипов.
Разработка и обучение моделей классификации авторских текстов по психотипам.
Выполнение типирования авторских текстов из ранее неклассифицированной выборки с применением различных алгоритмов классификации.
Результаты исследования отличаются следующей научной и практической новизной
Получило дальнейшее развитие применение методов машинного обучения на основе исследования с помощью пакета RapidMiner на обучающей выборке с поэтапным анализом, что позволило провести классификацию текстов по определению психотипа авторов.
Усовершенствована модель классификации психотипов на основе использования различных подходов к классификации текстовых массивов, что позволяет определить принадлежность автора текста к психотипу.
Получила дальнейшее развитие методика разработки моделей классификации психотипов с использованием алгоритмов рекуррентных нейронных сетей и полносвязной многослойной нейронной сети для типирования авторских текстов.
РАЗДЕЛ 1. ИССЛЕДОВАНИЕ МЕТОДОВ АНАЛИТИЧЕСКОЙ ОБРАБОТКИ АВТОРСКИХ ТЕКСТОВ
1.1. Определение понятия “психотип”
Различные школы психологии используют отличные одна от другой психологические типологии, но далеко не все из них при определении типов личности связывают с психологическими особенностями речевые и языковые отличительные характеристики. А типологий, использующих в качестве критериев при проведении типирования лингвистические характеристики, практически нет. Теперь, самое время разобраться с базисным понятием психолингвистики – понятием психотипа.
Древнегреческий врач Гиппократ был одним из первых, кто предложил свою версию классификации людей по свойственным им чертам поведения [16]. Он по-прежнему популярен среди специалистов и сегодня. Гиппократ предложил ассоциировать разделение на психотипы в пропорциях жидкостей тела:
- кровь (сангвис);
- черная желчь (меланхолическая дыра);
- лимфа (мокрота);
- желтая желчь (дыра).
По мнению ученого, распространенность одного из них позволяет разделить людей на четыре типа:
1. Оптимистический. Большое количество крови указывает на подвижную личность и веселый нрав.
2. Флегматичный. Из-за большого количества лимфы становится медленным и сбалансированным.
3. Холерический. Взрывной, импульсивный характер, указывает на избыток желтой желчи.
4. Меланхолический. Большое содержание черной желчи провоцирует склонность к страху и печали.
Многие века ученые работали над изучением человеческого темперамента. Были разработаны и дополнены различные теории. Названия психотипов, дошедшие до наших дней, остались неизменными, однако суть изменилась.
Под темпераментом принято понимать совокупность врождённого психологического развития в сочетании с процессами возбуждения и замедления в мозге. Меланхолику соответствует слабый тип с высокой активностью нервной системы, холерику – сильный, взрывной темперамент. Флегматик может быть стабильно уравновешенным, но инертным, а сангвиник – уравновешенным и стабильным.
Со времён древности философы и учёные из многогранной человеческой сущности пытались выделить психотипы людей, классификация и принципы определения которых могли значительно отличаться. Познания в психологии основывались на наблюдении человека в различных ситуациях или на трудах учёных, предложивших определения типажей. Лишь в прошлом веке началось детальное изучение психологической природы человека.
Много веков трудились учёные над изучением человеческого темперамента. Развивались и дополнялись различные теории. Названия психотипов, дошедшие до наших дней, остались неизменными, однако, суть поменялась. Под темпераментом принято понимать совокупность врождённого психологического развития в сочетании с процессами возбуждения и замедления в мозге. Меланхолику соответствует слабый тип с высокой активностью нервной системы, холерику – сильный, взрывной темперамент. Флегматик может быть стабильно уравновешенным, но инертным, а сангвиник – уравновешенным и стабильным.
Характер – это проявление темперамента в социуме. Он может изменяться в течение жизни, проявляться по-разному в различных обстоятельствах. Однако, под свойствами характера можно считать только стабильные проявления, те, что присущи данной личности. Большую роль в формировании характера играет окружение, социальная группа, в которой находится индивидуум и развивает личностные качества человека. По научным данным, считается, что психотип – это совокупность ярко выраженных черт характера.
Обобщив вышеизложенное, сделаем заключение, что психотип – исключительно принадлежащая науке психология характеристика личности человека. При этом центральным понятием в психологии является понятие личности человека. Модель личности строится на таких базисных понятиях человеческого сознания как: способностей, темперамента, характера, волевых качеств, эмоций и мотивации. Такое понятие, как направленность является важным фактором для личности. Будучи сложной системой мотивов (идеалов, верований, способностей, желаний, убеждений, интересов, мировосприятия и т.д.), определяющая вектор поведения личности человека в различные социальных и культурных условиях она ярко характеризует личность человека. Не менее важным фактором векторизации личности является темперамент.
Все эти понятия проявляются в деятельности человека на всех уровнях его жизнедеятельности. Это касается и такого понятия, как манера выстраивания речевых конструкций. Некоторые специалисты использования данные особенности при построении своих классификаций личности. То, что человек относится к определённой группе психотипов, автоматически наделяет его речь чётко определёнными и ярко выраженными языковыми и собственно речевыми маркерами, выражающими наличие чёткой связи между такими понятиями как “личность” и “языковая личность” [4].
Учитывая обстоятельство, что каждому психотипу гарантированно соответствуют некоторые речевые и языковые лингвистические маркеры, позволяющие определить данный психотип путем разбора на составляющие текста, необходимо выбрать наиболее подходящую психологическую типологию.
1.2. Базис Карла Густава Юнга и соционика
Для определения базиса Юнга и последующего построения модели человеческой психики рассмотрим такой термин, как соционика.
Соционика - это наука, изучающая психологические особенности типов личности и отношений между ними. Наука соционики изучает механизм, с помощью которого человек воспринимает и оценивает полученную им информацию.
Соционика основана на четырех парах черт (также называемых дихотомиями), предложенных К. Г. Юнгом в первой половине XX века. Однако классификация Юнга была основана на поведении человека. В 1970-х годах литовский исследователь Aushra augustinaviciute [9] сопоставил четыре дихотомии личности и присущие им характеристики с учением А. Кемпинского. Это событие вызвало резонанс и привело к пересмотру ранее существущих характеристик (признаков) психологических основ личности. Как результат - образование нового подхода к произведению типирования человека, которым стала заниматься соционика.
Базисом учения соционики является выделение следующих наборов признаков психотипа, объединённых в пары (в дальнейшем мы будем называть эти пары признаков базисом Юнга - дихотомиями):
Рациональность/иррациональность. Данная пара признаков имеет свои корни ещё от классического учения К. Юнка. Юнг считал, что психика человека - это область непрерывного противодействия пары процессов человеческой психики: "восприятие" (процесс потребления информации человеком из вне) и "суждение" (анализ и ранжирование полученной информации с целью вынесения решения по этой информации). Несмотря на то, что пара этих процессов неразрывны и влияют друг на друга, всегда наблюдается доминирования одного над другим. У рациолналов превалирует рассудительность, поэтому, перед принятием решения о выполнении того или иного действия, мысленно спрашивают себя "зачем мне это". Лишь после принимают решение совершать или не совершать шаг. Рационалы же аналитически воспринимают мир, это предполагает дифференцирования обей картины, а только затем оценивание.
Иррациональный подход к мировосприятию предполагает синтетическое восприятие: оцениваются не элементы, а весь мир целиком. Так же им не свойственно проведение сравнения текущей ситуации с какой-либо иной - возможной. Это даёт им время на более быстрое принятие решений в экстремальных ситуациях, что даёт больше шансов на выживание. При этом доминирующая импульсивность не даёт им возможности проводить глубинный анализ своих поступков, что затрудняет процедуру восстановления последовательности своих шагов. Найти причину своих действий.
Пара логика/этика относится к рациональной дихотомии, так как эта дихотомия отвечает за проведение "логического рассуждения". Непосредственной задачей данной дихотомии проведение оценки наблюдаемого объекта с целью извлечения из него заданного набора признаков/характеристик, которые в дальнейшем станут факторами ответной реакции на этот объект. Параллельно с этим производится отбор признаков, имеющих значение в ближайшей перспективе. Но логика в принятии решений может работать своеобразно, принятие решения может основываться и на, достаточно абстрактным признакам, таким как: "опасная/безопасная", "холодно/жарко", "светло/темно" или "красиво/некрасиво", "плохо/нхорошо".
Таким образом логика в каждой из этих ситуаций рассматривает мир как множество элементов, подчиняющихся определенным законам (например, законы природы, законы общества, правила принятия решений и др.). Сознание логиков работает на выявление этих несоответствий и применение этих знаний на достижения собственных целей. И главный способ определить такие образцы состоит в том, чтобы сравнить, текущую ситуацию с подобной, чтобы понять, что это изменяется, если Вы удаляете или добавляете конкретную ситуацию.
Этика имеет совершенно иной взгляд на мир. В любой ситуации этика видит много действующих лиц, у каждого из которых свои интересы, намерения, желания. Часто такое восприятие можно перенести на неодушевленные объекты (например, гуманизацию машины или компьютерной технологии). Разделение на важную и неважную этику выглядит примерно так: если это важно хотя бы для одного из участников ситуации, то теперь важно ее рассмотреть.
Интуиция/сенсорика - это дихотомия восприятия. Данная дихотомия отвечает за способы восприятия человеком информации об окружающем мире. Сенсорика является основным информации из внешней среды, этому способствуют ощущения тела. Мир для него видится как нечто, что можно ощущать, трогать, с чем возможен обмен информацией. Данное чувство позволяет ощущать окружающие объекты в данное мгновение и данном месте.
Полной противоположностью является интуиция. Она совершенно не привязана к чувственным ощущениям, что позволяет ей с достаточно просто обращаться к различным источникам информации: нервные импульсы, память, фантазировать. Такое мировосприятие может сформировать мнение окружающих, что человек с превалированием интуиции выпадает из мира реального и находится в мире выдуманном. Но такое обстоятельство позволяет интуиту быть намного гибче, связывать между собой неочевидные события и явления, хорошо ориентироваться в ситуациях неопределённого стартового набора данных.
Интроверсия/Экстроверсия – данная дихотомия претерпела значительные изменения, что привело к тому, что данное понятие различается в всихологии и соционике.
Соционика рассматривает экстраверсию как качество личности, направленное на восприятие объектов (людей, чувств, событий). В противовес этому интроверсия заточена на принятие впечатлений от всего, что относится к мнимой теме.
Идея данной классификации основана на взаимоисключении одной из пар в каждой дихотомии. У любого человека присутствуют обе пары дихотомии, но одна из них явно преобладает на другой. Так же предполагается, что дихотомии являются взаимозависимыми и прекрасно сочетаются друг с другом в различных комбинациях. Например, рациональность сочетается с интроверсией или экстраверсией, интуицией или сенсорикой и т.д. Подобные комбинации, содержащие явно доминирующие дихотомии образуют TИM или социотип. ТИМ определяет набор индивидуальных особенностей, составляющих общие представление о конкретном человеке. Таких социотипов выделяют 16 (24 = 16) штук – это все возможные комбинации дихотомий в человеке.
ТИМ или соционический тип определяется выполнением следующего набора шагов. Определение ТИМа начинает формироваться либо для рационала, либо для иррационала.
Для рационала, в первую очередь определяется свойство "логика" или "этика", следующим шагом записывается "интуиция" или "сенсорика", на последнем шаге выбирается элемент пары – "интроверсия" или "экстраверсия". Несколько иная очерёдность формирования ТИМа для иррационала: сначала определяется значение пары "интуиция" или "сенсорика", после чего "логическа" или "этика", и на последнем шаге - "экстраверсия" или "интроверсия". Например, если сформировался такой набор дихотомий: логика, интуиция, интроверсия, в связке с рациональностью, то получим набор признаков, соответствующий ТИМу с названием "логический интроверт". В случае сочетания описанных признаков с иррациональностью – получим ТИМ с названием "интуитивно-логическим интровертом".
Но такой подход к записи ТИМов крайне неудобен, в следствии чего его записывают одним из двух вариантов: LII и OR или используют псевдонимы. Во втором случае используют или имена известных деятелей, или имена литературных персонажей.
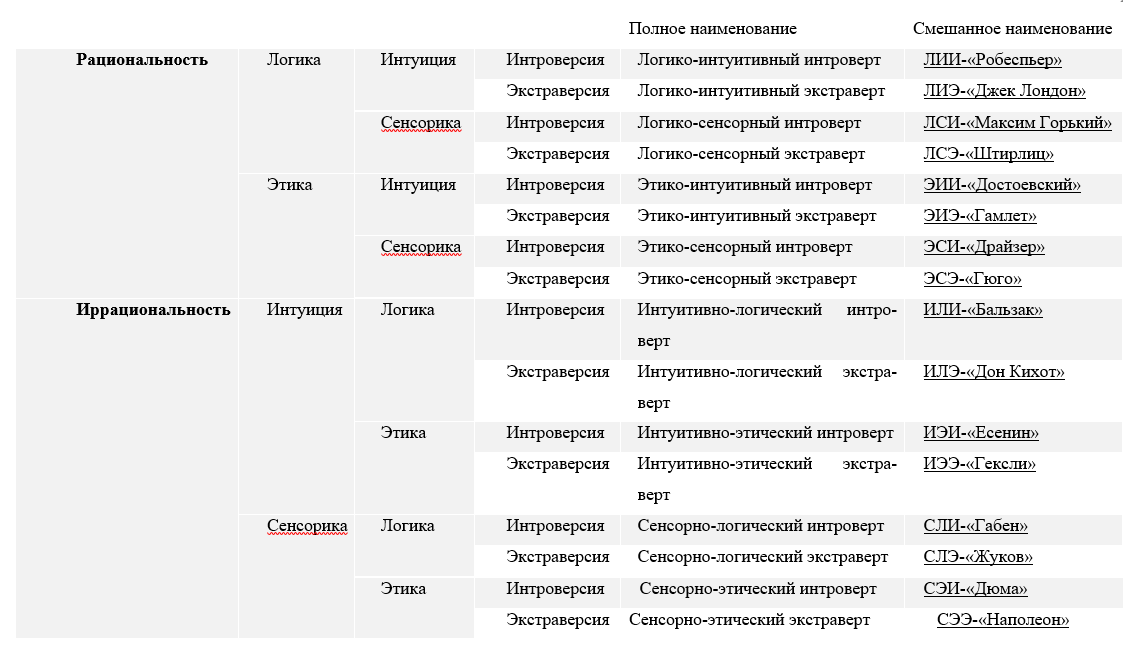
Полный список ТИМов с характеристиками социотипов и их кодов рассматривается в таблице 1.1.
Таблица 1.1
Список признаков соционических типов и их обозначений
1.3. Алгоритмы и методы анализа данных
Сравнительный анализ классификаторов.
Классификатор — это инструмент для добычи данных, который принимает некоторое количество данных, представляющих то, что мы хотим классифицировать, и пытается предсказать, к какому классу эти новые данные должны принадлежать. Рассмотрим наиболее часто используемые, согласно исследованиям, алгоритмы классификации:
ЕМ-алгоритмом это правило по которому строятся алгоритмы шагового типа (итерационные алгоритмы), задачей которых является нахождение с помощью применения численных методов экстремума целевой функции при решении различных задач оптимизации процессов.
Например, с целью нахождения наибольшего правдоподобия в ситуациях, при которых заданная функция правдоподобия сложна со структурной точки зрения, из-за чего другие методы неэффективны в прикладной статистике.
В большинстве случаев цель ЕМ-алгоритма сводится к решению двух типов задач.
Первый пит предполагает решение задач статистического характера, особенностью которых является проведение анализа неполных данных, что заключается в отсутствии определённого объёма статистических данных по различным причинам.
Ситуация, требующая решения статистических задач, в которых функция правдоподобия не имеет решения ввиду сложности структуры, но даёт возможность найти решения при вводе дополнительных отсутствующих величин относится ко второму классу задач для функции ЕМ. Наиболее яркими задачами второго класса это задачи распознавания образов и восстановления изображений. С математической точки зрения такие задачи можно отнести к кластерному анализу, задачам классификации или распознавания образов, дифференциации заданного набора данных.
Название алгоритма означает "ожидание-максимизация, что происходит от "expectation-maximization". Подобное название непосредственно связано со схемой работы алгоритма, которая предполагает при каждой итерации выполнение двух шагов – расчёт и получение математических ожиданий (expectation) и максимизацию (maximisation). Работа алгоритма базируется на таком понятии, как пошаговые вычисления оценок максимального правдоподобия. Такая методика была предложенна в 1977 г.
Идея работы алгоритма заключается в предположении того, что анализируемый набор данных может быть смоделирован с помощью линейной комбинации многомерных нормальных распределений [31]. При этом, основной целью становится оценивание показателей параметров распределения, которые максимизируют логарифмическую функцию, являющуюся критерием определения качества модели. Выдвигается предположение, что данные каждого кластера распределяются согласно единому заданному закону, а именно, нормальному распределению (рис. 1.1).
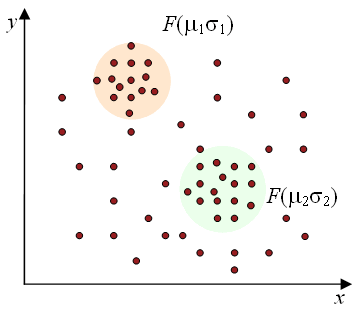
Рис. 1.1. Модель EM
Данное предположения позволяет определить искомые параметры - математическое ожидание и дисперсию.
Представим каждый имеющийся объект N-мерным вектором. В качестве исходных данных будем рассматривать M векторов
Xm = (xm1, xm2,...,xm N), m=1,...M. (1.1)
В алгоритме EM-кластеризации предполагается, что известно количество кластеров. Через K обозначим количество кластеров. Каждый кластер описывается N-мерным нормальным распределением, т.е. для каждого кластера задан вектор математических ожиданий
μk=(μk1, μk2,...,μkN), k=1,...K (1.2)
и вектором дисперсий (мы считаем, что матрица ковариации - диагональная)
σ2k=(σ2k1,σ2k2,...,σ2kN), k=1,...K. (1.3)
Целью алгоритма является построение вероятностей, что объект Xm принадлежит кластеру k. Эти вероятности обозначаются через gmk.
Улучшение качества вычисление происходит при итеративном выполнении алгоритма. Прекращение работы произойдёт тот в момент, когда показатели вычислений будут соответствовать заданному уровню точности модели. Мерой становится стабильно выполняемая «шаг за шагом», увеличивающаяся статистическая величина - логарифмическое правдоподобие. Целью алгоритма является оценка средних значений CC, ковариаций RR и весов смеси WW для функции распределения вероятности, описанной выше.
Рассмотрим ряд преимуществ EM-алгоритм:
Хорошая статистическая база.
Увеличение сложности происходит линейно, в зависимости от объема данных.
Стабильная работа при наличии шумов и потерь в данных.
Возможность построения любого числа кластеров.
Быстрая сходимость при верно выбранной инициализации.
Среди недостатков:
Не всегда выполняется предположение о нормальности всех измерений данных.
При ошибке при инициализации может замедлится сходимость алгоритма.
Алгоритм EM доступен в Weka.
Метод k-means относится больше к методам кластеризации текстов. Являясь одним из простых методов классификации, он показывает не самые лучшие результаты своей работы. Идея его работы состоит в том, что он разбивает заданное множество элементов векторного пространства на предварительно определённое исследователем число кластеров k. Алгоритм работает таким образом, что стремится сделать минимальным среднеквадратичное отклонение на точках, принадлежащих каждому из кластеров. При таком подходе при каждой следующей итерации осуществляется новый расчёт центра масс для каждого кластера, полученного на предыдущем шаге. После чего происходит повторное разбиение векторов на кластеры, ориентируясь на показатель наибольшей близости нового центра к выбранной. Алгоритм прекратит производить разбиение векторов тогда, когда на одном из следующих шагов изменения кластеров перестают происходить.
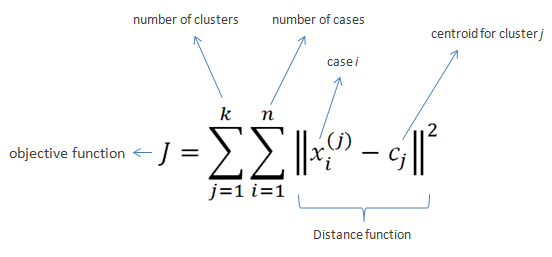
Рис. 1.2. Модель k-means
Алгоритм работы:
Группирует данные в k группы, где k заранее предопределено.
Выбрать k- точки наугад, как центры кластеров.
Назначьте объекты их ближайшему центру кластера в соответствии с Евклидова функция расстояния.
Вычислите центроид или среднее значение всех объектов в каждом кластере.
Шаги 2, 3 и 4 повторяются до тех пор, пока одинаковые точки не будут назначены каждому кластеру в последовательных раундах.
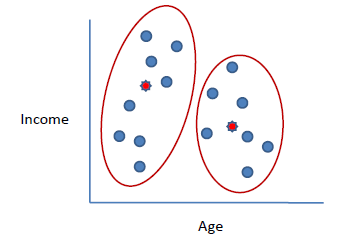
Рис. 1.3. Разбивка на кластеры
Недостатки алгоритма k-means:
1. необходимо заранее знать количество кластеров. Предварительно необходимо провести преобразования, направленные на выявление предполагаемого количества требуемых кластеров. После этого выполнялся классический алгоритм k-means, который давал более точные результаты.
2. Алгоритм достаточно зависим от выбора центров кластеров. При классическом методе кластеризации предполагается выбор кластеров в случайном порядке, что достаточно часто может являться источником еточностей в работе алгоритма. Как вариант для минимизации рисков в качестве центов можно выбирать самые отдаленные точки кластеров.
3. Наблюдается проблема кластеризации в тех случаях, когда объект не принадлежит ни одному кластеру либо принадлежит к разным кластерам в равной степени.
Наивный байесовский классификатор (Naive Base) - это не единственный алгоритм, а целое семейством алгоритмов, объединяет которые общее предположение о следующем: каждое из свойств классифицируемых объектов является независящим от всех остальные свойств.
При использовании метода Байеса при классификации текстов, возникает необходимость применения классификатора отдельно для каждой категории. При этом решение о принадлежности, так же принимается для каждой категории в отдельности.
Алгоритм Байеса определяет вероятность свершения события, основываясь на предположении выполнения другого события, которое уже наступило. Математическая интерпретация Теорема Байеса:
![]() (1.4)
(1.4)
где A и B - события, а P (А) - вероятность.
Метод Бейеса пытается предположить результат наступления события A, опираясь на факт наступления события B. Событие B также называется доказательством.
P (A) - это априори A (предполагает наступление события А в отсутствии тому подтверждения). Для доказательства достаточно значение атрибута неизвестного экземпляра (в текущем примере событие B).
P (A | B) - апостериорная вероятность B, т. е. вероятность события после доказательства.
Рассмотрим пример.
Предположим, имеется некий набор данных о пациенте, среди которых можно выделить: пульс, возраст, пол, вес, рост и домашний адрес. Свойства можно считать независимыми друг от друга. Очевидным является факт независимости роста человека и его домашнего адреса, собственно, как и отсутствие связей между его и полом.
Но тут важно не пропустить те свойства, которые всё же зависимы:
при увеличении роста имеется вероятность и увеличения веса человека;
при повышении уровня холестерина вес человека с большой вероятностью так же увеличится;
таким же образом можно выявить связь между холестерином и пульсом человека.
Формулу классификации в общем виде можно представить так:
![]()
(1.5)
Эта формула в зависимости от значения свойства 1 и свойства 2 определяет вероятность выделения класса А. Если имеется свойство 1 и свойство 2, то делается вывод о том, что эти свойства и принадлежат классу А.
Положительные свойства:
Относительная простота реализации. Классификатор Байеса использует простые вычисления. Действия при его выполнении заключаются в подсчете, умножении и делении.
Сразу после составления таблиц вероятностей, для осуществления классификации неизвестного элемента требуется выполнить вычисление вероятностей для всех классов, а после этого выбрать наиболее вероятный класс.
При всей его простоте, классификатор Байеса предоставляет крайне точные показатели классификации. Как подтверждение этому можно сказать, что его эффективность была зафиксирована при задачах классификации спама.
LSTM сети - краткосрочная память (Long short-term memory), обычно называемая LSTM-сетями — это особый вид рекуррентных нейронных сетей, способных к запоминанию долговременных зависимостей [27]. Они были введены Сеппом Хохрайтером и Юргеном Шмидхубером в 1997 году и были использованы и развиты многими исследователями в своих работах. LSTM сети очень хорошо себя зарекомендовали и по этой причине их применяют в широком диапазоне задач.
Особенность LSTM сетей в возможности запоминать промежуточные состояния прекрасно подходят для решения проблемы связанной с понятием долговременных зависимостей. Данные сети даже без дополнительного обучения запоминают информацию на долгий период.
В общем виде рекуррентная сеть представляет собой простую связанную последовательность повторяющихся простых нейросетей.
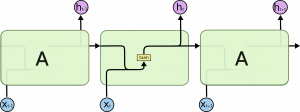
Рис. 1.4. Повторяющиеся модули в стандартных рекуррентных сетях, содержащие один слой
LSTM-сети аналогично рекуррентным сетям можно рассматривать как последовательность простых нейросетей, однако структура повторяющиеся модули организована значительно сложнее: в своей основе она использует не однослойные нейронные сети, а состоящие из четырёх слоёв, организованную своеобразным способом.
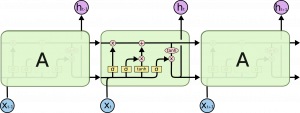
Рис. 1.5. Повторяющиеся модули в LSTM-сети, содержащие 4 слоя
Перечень используемых в изображении нейросетей условных обозначений приведен на рис. 1.6.

Рис. 1.6. Повторяющиеся модули в LSTM-сети
В приведенной выше диаграмме каждая линия обозначает вектор, передающий данные с выхода одного узла на вход другого. Розовый круг обозначает поэлементные операции, такие как сложение векторов. Желтые прямоугольники обозначают обучаемые нейросетевые слои. Соединяющимися линиями обозначена конкатенация, а разделяющимися — копирование.
Базовая идея LSTM-сетей состоит в:
Что из себя представляют LSTM-сети? Прежде всего имеется ввиду состояние ячейки, на изображении в виде горизонтальной линии, проходящей сквозь верхнюю часть изображения.
Состояние ячейки можно сравнить с работой ленты конвейера: оно проходит через цепочку всех элементов сети, изредка осуществляя слабые линейные взаимодействия. Что означает возможность проходит, не взаимодействуя с элементами.
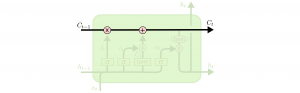
Рис. 1.7. Базовая модель LSTM-сети
Способность сети добавлять или удалять информацию в ячейке, тщательно регулируется структурами, называющимися вентилями.
Вентилями называют структуру, которая контролирует передачу информации. В её основе используется нейронный слой и сигмовидная функция, выполняющая, функцию активатора. Взаимодействуя вместе они выполняют операцию поэлементного умножения.
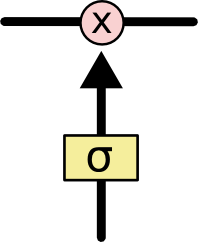
Рис. 1.8. Работа синопса в LSTM-сети
На выходе сигмоид выдаёт два бинарных значения – 0 или 1, на основании чего принимается решение о блокировании или пропуске каждого элемента вектора. Параметр 0 является признаком блокирования вектора, а значение равное 1 — «пропустить полностью»
LSTM имеют три таких элемента для защиты и контроля состояния ячейки.
Пошаговый анализ работы LSTM-сети.
Первый шаг в LSTM сети — это решение, какую информацию необходимо выбросить из состояния ячейки. Решение формируется сигмовидным слоем называемым входным вентилем. Он обозначен, как ht−1 и xt и имеют числовой выход со значением между 0 и 1 для каждой ячейки состояния Ct−1. 1 обозначает «полностью сохранить», 0 — «полностью избавиться».
К примеру, рассмотрим лингвистическую модель предсказания слова, основываясь на предыдущих словах. В подобной задаче ячейки могут содержать пол рассматриваемого объекта для использования верного местоимения. Однако, когда мы видим новую тему, можно забыть пол старого объекта.
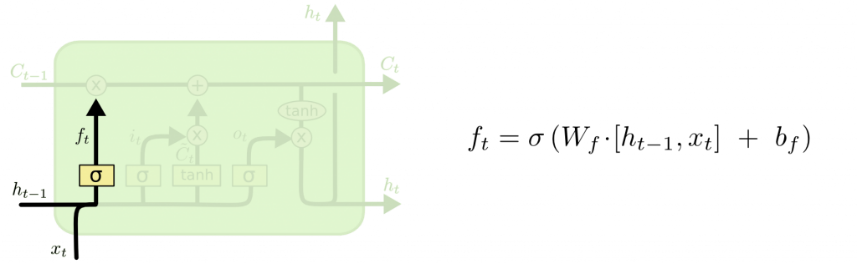
Рис. 1.9. Движение сигнала в LSTM-сети
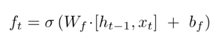 (1.6)
(1.6)
На следующей итерации определяется тип информации, которую необходимо поместить и сохранить в состоянии ячейки. Рассмотрим две составляющие данного шага:
Определением того, какие значения подлежат обновлению занимается входной вентиль, а tanh-слой формирует вектор вновь появляющихся претендентов на значения параметра Ct, которые так же возможно поместить в состояние. Следующий шаг предполагает выполнение слияния первого и второго векторов с целью обновления состояния.
В примере с языковой моделью, мы хотим добавить пол нового объекта в состояние ячейки для замены устаревшего.
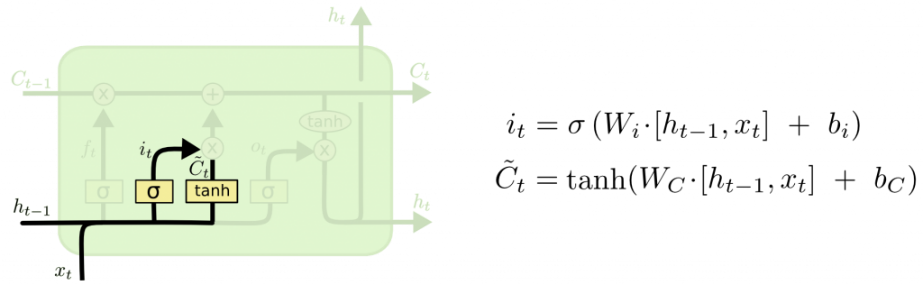
Рис. 1.10. Обновление значения в LSTM-сети
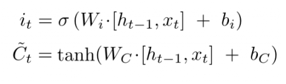 (1.7)
(1.7)
Далее происходит приведение состояния ячейки Ct−1 к новому состоянию, соответствующему ячейке Ct и записанного в неё на предыдущем шаге.
Далее необходимо осуществить обнуление состояния ячейки, для сего выполняется умножение прошлого на значение ft. После происходит увеличение на it∗Ct.
В случае с лингвистической моделью мы забываем информацию о старом субъекте и запоминаем новую информацию, определенную на прошлом шаге.
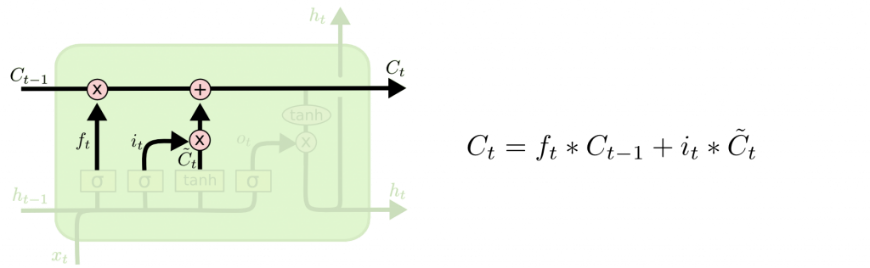
Рис. 1.11. Замена значения в LSTM-сети
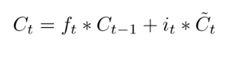 (1.8)
(1.8)
Наконец, алгоритм должен принять решение, что будет присутствовать на выходе. Для этого в первую очередь запускается сигмоидный слой, определяющий какая часть состояния ячейки будет передана на выход. После чего состояние ячейки подается на функцию tanh (выходные значения между -1 и 1) и умножается на выход сигмовидного вентиля, определяющего частичность выхода состояния.
В примере с лингвистической моделью, это может быть предмет, увиденный сетью и требующийся для вывода информации, имеющей отношение к глаголу. Например, определение множественного или единственного числа субъекта для определения формы глагола - следующего далее.
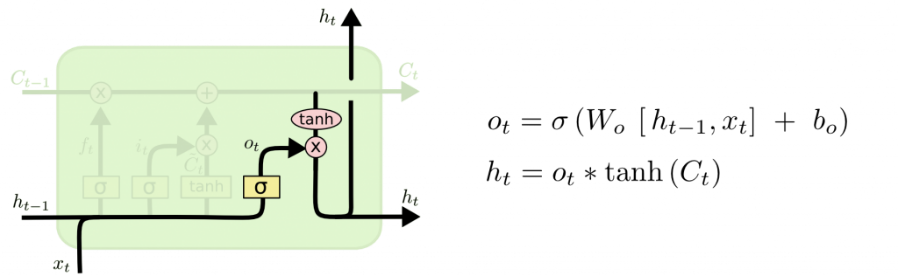
Рис. 1.12. Определение значения глагола в LSTM-сети
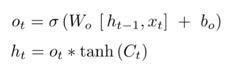 (1.9)
(1.9)
1.4. Аналитическая обработка текста (Text mining), области применения данной технологии
Атрибуция текста – это одно из направлений в исследования текстов, задачей которого является идентификация автора документа. Второй задачей становится выявление каких-либо сведений об авторе текста или скрытых закономерностей. Атрибуция решает две группы задач - это идентификационная и диагностическая группа задач.
Данная методика даёт возможность провести исследование неструктурированных текстов используя в качестве критериев следующие лексические характеристики: пунктуационный и орфографический уровни, синтаксический и лексико-фразеологический, а также стилистический уровень.
Рассмотрим кратко характеристики описанных слоёв разложения:
Пунктуационный уровень позволяет раскладывать исследуемые текста на такие единицы, как знаки препинания, характерные ошибки и выявления их частотной характеристики.
Орфографический уровень, позволяет сделать выводы, исходя из результатов анализа, результатом которого является вывод о соответствии слова каким-либо орфографическим нормам. При этом происходит определение имеющихся ошибок в словах.
Синтаксический уровень выявляет закономерности и особенности стилистической компоновки предложений, использование автором текста присущих ему конструкций предложения, порядок слов. На данном уровне принимается во внимание даже синтаксические ошибки. Данный тип анализа предоставляет достаточно широкие возможности классификации текстов и напрямую конкурирует с анализом по «мешку слов».
В общем условно методы анализа текстов можно разделить на две группы – экспертные и формальные. Методами экспертного уровня занимаются психологи-теоретики, используя различные сертифицированные методики опираясь на проведение анкетирования. Формальный метод подразумевает применение математических алгоритмов, построенных на базе теории вероятностей и математической статистики. Также широко используются алгоритмы кластерного анализа и методы машинного обучения.
По аналогии с методами распознавания образов, методы машинного исследования опираются на сравнение набора признаком текстов. После проведения ряда преобразований над текстом, алгоритм превращает текст (его характерные черты) в числовой вектор, т.е. производится векторизация текста. Ключевым моментом данной процедуры является выделение и группировка присущих автору особенностей (характеристик) и преобразование данного массива в набор векторов (векторизация текста). Каждый вектор при этом отвечает за определённую стилистическую особенность в написании текста. После процедуры векторизации текстовый массив можно рассматривать в качестве координаты (точки) в n-мерном векторном пространстве. Аналогичным вектором n-мерного пространства становится и психотип автора текста. Параметрами такого вектора является набор характеристик авторского текста.
Подобными исследованиями занимается технология интеллектуального анализа текста - Text Mining. Как ранее говорилось, её задача непосредственно лежит в области преобразования неструктурированных текстовых в высококачественную информацию в виде n-мерных кластеров структурированных данных. Собственно, дальнейший анализ относится к методам Data Mining. Это происходит посредством построения шаблонов на основе ранее описанных методов и выявленной ими информации, по которым, в дальнейшем, происходит построение и обучение модели. Такая технология, благодаря мощным вычислительным ресурсам и различным позволяет «просеивать» большие объёмы неструктурированной текстовой информации и обнаруживать в них скрытые закономерности, которые человеку невозможно выявить самому, даже тратя на это много времени и ресурсов.
При использовании технологии Text Mining, происходит глубокий анализ текстовой информации, результатом которого является получение массива информации о зависимостях и связях в неструктурированном тексте. Для дальнейших исследований эта информация предоставляет обширные возможности и позволяет интерпретировать и использовать выявленные корреляционные зависимости для решения различных задач.
Набор подобных сведений можно использовать совершенно в различных исследованиях, например, при проведении прогнозирования роста финансовых рынков, исследовании настроений избирателей. Сейчас такого рода исследования проводятся на уровне трупных финансовых или политических игроков, но за ними наблюдается явная перспектива в использовании на «бытовом» уровне.
Подытожив, можно сказать, что технология Техt Mining выполняет две основные задачи: создаёт массив в виде набора структурированной информации, путём извлечения её из тактовых массивов данных. Вторая задача заключается в оценивании качества результатов. Анализ на основе технологии Text Mining предполагает применение ряда методов, среди которых: классификация и кластеризация текстов, проведение смыслового анализа текста с выявлением закономерностей и построением моделей, выявление общих признаков и характеристик в массивах текстов.
Главной целью проведения столь обширных и сложных преобразований является переход от неструктурированного текстового кластера к структурированной информации, доступной для дальнейшего анализа и построения шаблонов. Происходит это путём векторизации неструктурированных текстовых документов.
На основе подобного набора данных уже можно построить модель для проведения классификации или кластеризации с целью прогнозирования результатов. Технология Text Mining представляет собой связку алгоритмов лингвистического и статистического анализа, работа которых направлена на преобразование неструктурированного текста, с применением моделей машинного обучения.
Такие технологии активно применяются в корпоративной сфере с целью управлением процессами решения бизнес-задач.
Технология интеллектуального анализа данных предоставляет возможность выделить и исследовать информацию из таких массивов. Полученные данные в виде набора фактов, взаимосвязей достаточно сложно получить, используя ручные или какие-либо иные автоматизированные средства.
Так каков процесс обработки текста в технологии Text Mining?
Рассмотрим базовые шаги и методики данной технологии:
1. Предобработка текстовой информации, которая заключается в сборе неструктурированных данных для проведения дальнейшего анализа. Подобную информацию можно достать вручную или использовать дополнительный метод – WebMining, позволяющий автоматически «парсить» и извлекать данные из сети ИНТЕРНЕТ.
2. Можно прибегнуть исключительно к методам статистического анализа данных и остановиться на анализе выявленных ключевых характеристик. Так же можно дополнить статистические характеристики методами лингвистического анализа текста.
3. Количественный анализ текста – направлен на выявление скрытых семантических или грамматических связей в тексте, с целью формирования семантического ядра текста. Данная область исследований непосредственно связана с соционикой. Затем, анализируя семантическое ядро текста возможно осуществить психологическое профилирование автора на основе полученного семантического ядра текст или другие сходные операции.
4. Выявление перекрестных ссылок – выявление набора признаков, относящихся к одним и тем же объектам.
5. Выявление взаимосвязей между фактами и событиями – предполагает осуществление попытки выявления логической структуры текста.
6. Смысловой анализ – такой подход называют так же «сантимент анализом». Его задача заключается в анализе и выявлении из текста скрытой оценки в виде мнений пользователей, настроений, например, в отзывах к фильмам.
7. Выявление шаблонов – позволяет понять, в каких шаблонах в тексте заключены те или иные смыслы.
Целями применения подобной технологии могут быть совершенно различны, начиная от финансовой сфера, заканчивая военными или исследовательскими технологиями.
Среди наиболее популярных технологий можно выделить такие:
1. Корпоративная бизнес-аналитика, основанная на технологии работы с большими массивами - Data Mining, корпоративный шпионаж.
2. Лингвистика.
3. Военное направление, безопасность.
4. Научная и исследовательская деятельность.
5. Отслеживание публикация в печатных изданиях.
6. Классификация текстов путём исследования ЕЯ.
7. Делопроизводство и электронные исследования.
8. Мониторинг социальных сетей с целью определения настроений пользователей.
9. Извлечение смысловых характеристик в тексте.
10. Поиск информации по заданным критериям.
Остановимся на методологии проведения классификации (classification), в соответствии с целью данного исследования. Для отнесения документов к той или иной категории, в технологии анализа используется статистические корреляции.
Задача классификации является базовой в интеллектуальном анализе текстов. Её смысл заключается в отнесении элемента массива к одной из множества категорий, ориентиров чего является подготовленная контрольная выборка. Специфика технологии Text Mining состоит в том, что она позволяет работать с огромным массивом объектов и их атрибутов. По этой причине, в процессе анализа используют различные механизмы оптимизации атрибуции.
Ещё одно сходное направление – это кластеризация данных.
Решение задачи классификации состоит из четырех последовательных этапов:
Этап ввода данных (input) – получение неструктурированных данных в виде корпуса текстов из заданных источников. Такими источниками могут выступать комментарии пользователей, статьи, отчёты программ и др.
Предобработка текста (preprocessing) – состоит в преобразовании текстовой информации в структурированный вид, как правило векторизация текста. Данный вид должен быть понятен модели.
Построение и обучение модели данных (patternddiscovery).
Проверка работы модели (patterncanalysis) получение и анализ готового массива данных.
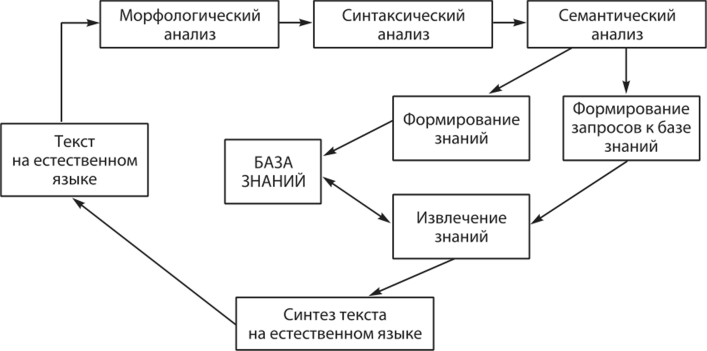
Рис. 1.13. Общая схема смыслового анализа и синтеза текстов
Если рассмотреть весть процесс аналитической обработки неструктурированных данных в виде текста, от постановки задачи до построения моделей, то в основе этого процесса лежит методология, получившая название Knowledge Discovery in Databases (KDD) — выявление знаний в базах данных [29].
Методология KDD представляет собой полуавтоматизированный процесс исследования Bigdata, целью которого и является выявление скрытых в них зависимостей или шаблонов. При этом методология не подразумевает поведения никаких предварительных работ по выявлению данных о характере скрытых структур и зависимостей.
На первом этапе KDD проводятся предварительное осмысление задачи и определение совокупности данных, на которых будет строиться последующий анализ, а также выборка данных из источника (источников).
На втором этапе осуществляется предобработка данных, включающая операции очистки данных (заполнение пропусков, устранение шумов, аномалий и противоречий), обогащения данных путем добавления полезной для дальнейшего исследования информации (справочников, словарей и т.п.), понижения размерности пространства признаков. Цель этапа предобработки — подготовка качественных данных, корректных с точки зрения используемых методов Data Mining. Как показывает практика, в бизнес-задачах этот этап является наиболее трудоемким и занимает 80—90% времени исследователя от общего времени решения задачи.
На третьем этапе выполняется трансформация предобработанных данных. Данные преобразуются в соответствии с требованиями дальнейшего анализа. Так, могут потребоваться приведение типов, преобразование даты, приведение к «скользящему окну», нормализация данных. Например, для осуществления прогнозирования необходимо преобразование к «скользящему окну», для кластер-анализа данные следует нормализовать.
На четвертом этапе к предобработанным и трансформированным данным применяются методы Data Mining, строятся и апробируются информационные модели, шаблоны, служащие для нахождения знаний.
На заключительном, пятом, этапе проводятся интерпретация человеком обнаруженных моделей и шаблонов и применение полученных знаний в бизнес-приложениях.
Обратим внимание на то, что методология KDD предполагает выполнение пяти основных процедур, комбинируя которые происходит процесс интеллектуального анализа данных. К этим процедурам относятся операции выборки данных, предобработки данных, трансформации данных, построения моделей и интерпретации полученных результатов.
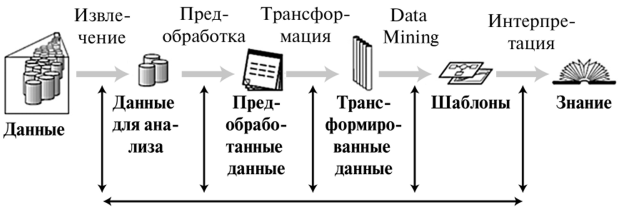
Рис. 1.14. Процесс обнаружения знаний в базах данных
Важность методологии KDD заключается в возможности тиражирования полученных в результате ее применения знаний, так как разработанные экспертами и аналитиками технологии получения знаний могут быть автоматизированы и внедрены в рамках организации в бизнес-процессы принятия решений. Тем самым сотрудники организации, не являющиеся ни экспертами, ни специалистами в области анализа данных, могут в своей повседневной деятельности применять формализованные подобным образом знания.
РАЗДЕЛ 2. ИССЛЕДОВАНИЕ И ВЫБОР АЛГОРИТМОВ КЛАССИФИКАЦИИ ДАННЫХ И ПОДГОТОВКА ИСХОДНЫХ ДАННЫХ ДЛЯ КЛАССИФИКАЦИИ ПСИХОТИПОВ
2.1. Обзор продукта RapidMiner
В своей работе после детального обзора существующих программно-аппаратных и программных платформ было принято решение остановиться на продукте аналитического исследования текстов – RapidMiner.
RapidMiner в своей основе использует так называемые операторы, каждый из которых выполняет определённые действия.
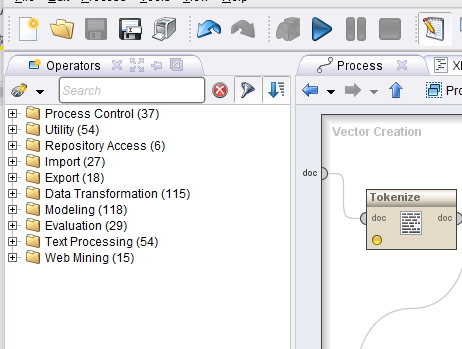
Рис. 2.1. Интерфейс Rapid Miner
После получения каждым операторам своего характерного набора данных, над ними производится анализ и преобразование, после чего выдаётся результирующий набор выходных данных.
Несмотря на то, что все операторы производят на данными совершенно разные операции, всё же входные и выходные данные имеют некоторую общую структуру, которая выглядит следующим образом:
Обобщённый Вход
Операторы получают на входе обучающую выборку, содержащую характеристики объекта. Каждый такой объект содержит определённое количество атрибутов, называемых также характеристиками, совокупность которых соответствует конкретному типу объекта. Все имеющиеся характеристики объекта в RapidMiner можно условно разделить на "номинальные" и "числовые" характеристики:
Первый тип работает с числовой информацией, а второй тип атрибутов может принимать все остальные типы, такие как, например, объект.
В программе принято различать два типа атрибутов: целевые и входные характеристики. Отличие заключается в том, что целевые атрибуты используются алгоритмом для обучения моделей классификаторов, в то время, как входные – применяются для построения самих моделей. При это, и целевые, и входные параметры принимают числовыми и номинальные значения.
Обобщенный Вывод:
В результате подобных действий в качестве итогового результата получается готовая модель, способная производить прогностические операции на новых, ранее не исследуемых, массивах данные, единственным критерием при этом требование к соответствию атрибутов нового массива атрибутам обучающей выборки.
Наивный байесовский оператор (NBC):
NBC подключает модель байесовского классификатора, суть работы которого сводится к обыкновенной вероятностной классификации, основанной на теореме Байеса. Наивным он называется по той причине, что рассматривает все атрибуты объекта как независимые друг от друга сущности.
Например, дерево можно отнести к классу лиственных, если оно имеет листья, кору, листья опадают осенью, толщину и высоту ствола. При этом, несмотря на то, что эти признаки могут оказывать влияние друг на друга, Байесовский классификатор расценивает их как полностью независимые, и каждый из них оказывает одинаковое влияние на отнесение объекта к данному классу.
Пусть X – множество объектов, Y – конечное множество имён классов, 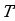 =
=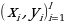 исходная выборка, где
исходная выборка, где 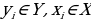 . Итак, данный оператор представляет из себя байесовский классификатор, в основе которого лежит теорема Байеса об условной вероятности.
. Итак, данный оператор представляет из себя байесовский классификатор, в основе которого лежит теорема Байеса об условной вероятности.

(2.1)

Где:
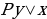 - вероятность того, что объект x принадлежит классу y
- вероятность того, что объект x принадлежит классу y
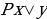 - вероятность встретить объект x среди всех объектов класса y
- вероятность встретить объект x среди всех объектов класса y
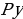 - априорная вероятность вероятность встретить объект y в классе Y
- априорная вероятность вероятность встретить объект y в классе Y
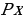 - априорная вероятность вероятность встретить объект x в классе X
- априорная вероятность вероятность встретить объект x в классе X
При отнесении объекта к определённому классу наивный Байесовский классификатор прибегает к алгоритму апостериорного максимума.

(2.2)
Таким образом, требуется вычислить все вероятности для всех известных классов и тот класс, на котором будет достигнута наибольшая вероятность, будет являться классом, к которому будет отнесён объект x. Так как знаменатель является константой и не оказывает влияния на выводы, изменим алгоритм оценки апостериального максимума.

(2.3)
Вход.
В качестве вводных данных оператору поступают уже пред обработанные данные, на основе которых обучается модель.
Выход.
В результате работы оператора получается обученная модель классификации (классификатор). После чего её можно использовать для классификации новых наборов данных.
Оператор нейронной сети (LSTM):
Данный оператор содержит структуру нейронной сети, аналогичную обыкновенной биологической. По аналогии, с которой данная нейронная сеть состоит из набора взаимосвязанных нейронов. Особенность нейронной сети состоит в возможности коррекции своей структуры, в зависимости от данных ей предоставляемых.
Среди большого числа видов нейронных сетей, акцентируем внимание на рассмотрении наиболее прогрессивного типа сетей – сети LSTM. Данная сеть использует при своём обучении алгоритм обратного распространения ошибок.
- Представление обучающих данных. т.е. данных учебных образцов, на вход нейронной сети;
- Обратное распространение ошибок;
- Корректировка шкалы.
Общая схема работы на примере модели Decision Tree.
Для начала создадим в RapidMiner общую схему взаимодействия описанных выше операторов. Построим процесс на примере оператора Decision Tree (дерево решений). На рис. 2.2 продемонстрирована общая процедура обучения и дальнейшего тестирования модели прогнозирования.
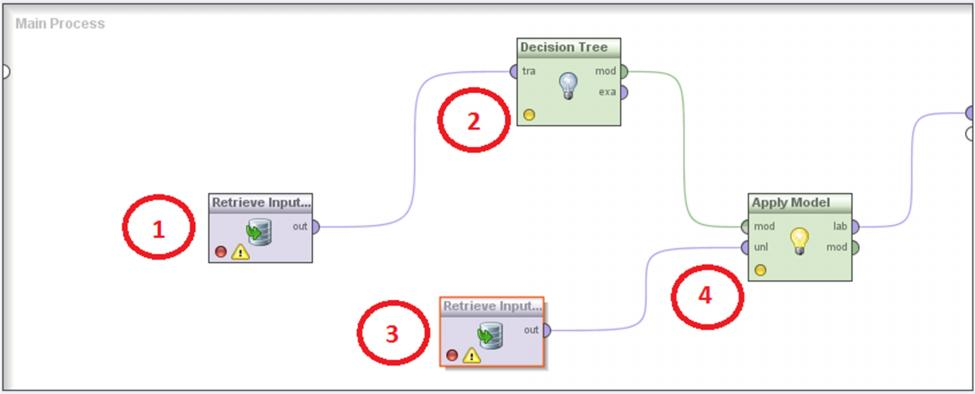
Рис. 2.2. "Схема модели обучения алгоритма Decision Tree "
Всего получаем четыре последовательных шага:
1. Импорт данных в виде готовой выборки;
2. После прогона через модель исходных данных – готовой выборки, результатом становится готова обученная модель на основе алгоритма дерева решений;
3. Следующим действием необходимо подгрузить к модели ранее не учувствовавшие в процессе обучения данные – тестовая выборка;
4. На завершающем этапе необходимо пропустить через обученную модель данные, подготовленные на шаге 3. Это необходимо для верификации работы модели, результатом чего служит вектор производительности модели.
2.2. Проблематика создания корпуса текстов
Перед началом проведения исследований оказалось, что серьёзной проблемой стало отсутствие достаточного количества русскоязычных текстов в открытом доступе, подходящих по тематике для проведения требуемых экспериментов. В результате чего для решения данной проблемы пришлось самостоятельно составить и разметить необходимые текста.
При поиске подходящей выборки стала задача выбора таких текстов, которые имели бы разговорный (обиходный) жанр. Ведь понятно, что существуют различные жанры текста, в которых могут использоваться и специфические тематики, и профессиональные оборы, и профессиональные слова в большом количестве. Всё это оставляет определённый след при проведении исследований.
По этой причине, за основу текстовой информации при исследовании было принято решение черпать необходимые данные из
сети ИНТЕРНЕТ. Причины, побудившие к использованию сети ИНТЕРНЕТ: во-первых, в сети существует большак количество тематических конференция, блогов, форумов, в которых возможно получить необходимый объём текстов. Более того, полученные тексты уже будут разбиты по необходимым нам для исследований категориям и в достаточном объёме.
Во-вторых, речь людей в сети ИНТЕРНЕТ, как правило, достаточно ограничена с точки зрения использования объёма слов, сложности построения предложений и лексических конструкций. Кроме того, записи людей в подобных местах отличаются эмоциональной окраской, выраженной в использовании большое объема специальных сочетаний символов – «смайликов».
Учитывая открытость и доступность данного источника, а главное - оцифрованность данной информации, было принято решение использовать именно этот ресурс для подготовки обучающей и тестовой выборки для обучения моделей классификации авторских текстов.
Итак, для создания необходимого объёма корпуса текстов текстовый материал брался извлекался из блогов участников интернет ресурса http://socioforum.su. Для извлечения данных использовалась технология WebMining.
Данный ресурс привлекателен тем, что содержит огромное количество пользовательских публикаций и, самое главное, все авторы имеют типизацию по базису К.Г. Юнга.
На стадии предобработки текстовой информации из полученных текстов были удалены все незначащие элементы, такие как цитаты, заключенные в кавычки, имена, интернет адреса, иные ссылки. Однако, и тут вощникают сложности, связанные с несоблюдением форумчанами правил цитирования – вставка цитат без кавычек влечёт в дальнейшем ряд сложностей при классификации авторских текстов.
Подготовительные работы занимают большой процент времени и предъявляют много сложностей, связанных с поиском достаточного количества материалов и, главное, нужного качества для реализации правильных исследований. В основном это касается обучения алгоритмов на базе нейронных сетей, для гарантированного обучения которых требуется значительно больший объём информации.
По итогам сбора данных удалось подготовить корпус текстов необходимого объёма, в среднем на одного автора блога приходится 270 записей, если интерпретировать в слова, то получается около 40100 слов на автора. Такого объёма текста является достаточным для выявления достаточного количества признаков в тексте, чтобы связать их с определённым психотипом. Записи каждого автора разбивались на двадцать различных файлов, принадлежащих к одной из категорий психотипа. В результате получился корпус текстов, состоящий из 320 текстовых файлов – соответствующих 16 социотипам по К.Г. Юнгу.
Речевые признаки психотипов.
Построение моделей классификации психотипов основано на речевых особенностях каждого из социотипов, описанных в предыдущих разделах работы.
Выделенные психологами ключевые характеристики текстов в соответствии с лингвистическими особенностями социотипов полезны тем, что не привязаны к содержимому конкретного текста и имеется возможность разложения в лингвистическом плане. К примеру, достаточно сложно сделать однозначный вывод о принадлежности человека к конкретной категории, руководствуясь лишь частотным показателем распределения различных символьных в тексте.
Для проведения исследований с классификацией документов по принадлежности к авторам соционических типов было решено провести исследование, основанное на двух методах классификации-использовании частотных характеристик лексем в массиве текстов и использовании наборов правил в соответствии с семантическими и лингвистическими характеристиками психотипов.
После этого осуществляется интексация и распределение терминов с использованием алгоритмов. В результате этих операций были извлечены и введены в словари следующие частотные характеристики:
1) Частотность употребления в текстах знаков пунктуации и специальных символов
Для анализа текстов и составления «мешка слов» были определены значащие спецсимволы (оказывающие вес при сравнительном анализе):
Таблица 2.1
Весомые спецсимволы и знаки, для классификации.
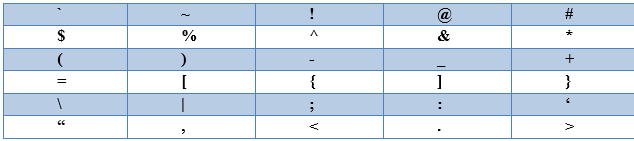
По аналогии с вычислением частоты употребления словесных токенов, каждому символу из таблицы по правилам алгоритма TF-IDF было произведено взвешивание таких показателей:
- показатель количество раз использования каждого знака в тексте, деленное на общее количество предложений в тексте;
- показатель отношения суммы предложений в тексте, которые содержат хотя бы один из вышеперечисленных символов к общему количеству предложений в тексте;
- показатель среднего количества всех символов из таблицы, встреченных в каждом предложении;
2) Числовые характеристики, говорящие о плотности употребления автором различных частей речи и их сочетаний
За основу были взяты следующие части речи и их комбинации:
Существительное, глагол, местоимение, краткая и полная форма прилагательного, наречие, служебная часть речи (союз, частица), а, так же два сочетания:
«Наречия+Имя прилагательное» и «Наречие+Наречие»
В соответствии с действиями, выполненными над вышеперечисленными элементами анализа, элементы текущей группы так же были преобразованы в числовые значения следующие показатели:
- показатель, равный отношению частоты использования какой-либо части речи или словосочетания к общему количество предложений в тексте;
- показатель, равный отношению общего количества предложений в тексте, включающих определённое количество раз сочетание токенов к общему количеству предложений.
В случае, когда характеристика некоторого слова отсутствовала в обозначенном словаре, такие сведения заносились в отдельную таблицу характеристик словарного запаса автора.
Не забыли и о частице «не» - частотность её употребления так же бала занесена в отдельную таблицу и аналогичным образом был высчитан коэффициент встречаемости.
3) Статистические сведения о плотности использования различных речевых оборотов и фразеологизмов
Что такое устойчивые словосочетания в призме психолингвистики? К понятию устойчивые сочетания относят традиционно устоявшиеся наборы словосочетаний, в нашем случае мы рассматривали речевые обороты и фразеологизмы. Причиной стало то, что употребление подобного рода конструкций достаточно легко определить и извлечь из текстового массива, при этом исследовав частотность употребления речевых оборотом можно получить представление о таких вещах, как уровень образованности автора, его настроение в момент написания текста.
Для осуществления подобного анализа было подготовлено несколько массивов (более 1000 элементов), содержащих следующие лексические обороты:
Обороты в функции предлога
Наречные и предикативные обороты
Вводные обороты
Обороты в функции союза и союзного слова
Обороты в функции частиц
Ниже, в таблице, приведены подобные словосочетания.
Таблица 2.2
Устойчивые словосочетания
| Обороты в функции предлога | Наречные и предикативные обороты | Вводные обороты | Обороты в функции союза и союзного слова | Обороты в функции частиц |
| без ведома | абы где | без всякого сомненья | если только не | ан нет |
| без оглядки на | абы как | без сомнения | затем что | вот то-то |
| без помощи | абы куда | без сомненья | затем чтоб | вроде б |
| без согласия | баш на баш | бери(те) выше | оттого что | вроде бы |
| без согласия на то | без боя | бес его (ее, их) знает | перед тем как | вроде как |
Источником послужил ресурс Национального Корпуса Русского языка (http://ruscorpora.ru/new/obgrams-PR.html )
Текста были проанализированы на предмет частотности и объема употребления в тексте таких речевых оборотов, по следующим метрикам:
- Отношение частоты употребления речевых оборотов из всего текста к общему количеству предложений текстового файла;
- Отношение объёма предложений, содержащих устойчивые сочетания к общему количеству предложений в тексте.
4) информация о количестве символов в словах и предложениях:
- Средний объём содержащихся в предложении символов, выражающий его размер в словах;
- Количество символов, в среднем, встречающихся в предложении.
Таблица 2.3
Признаки для социотипов (ТИМов)

РАЗДЕЛ 3. РАЗРАБОТКА МОДЕЛЕЙ КЛАССИФИКАЦИИ АВТОРСКИХ ТЕКСТОВ И ПРАКТИЧЕСКАЯ РЕАЛИЗАЦИЯ ТИПИРОВАНИЯ
Предобработка и индексация документов
На этапе предварительной подготовки текстового массива необходимо было выполнить следующие преобразования:
проведение токенизаци слов с помощью встроенных токенайзеров, удаление функционально значимых слов – не имеющих влияния на общую картину классификации: союзы, предлоги, артикли, имена собственные и др. После производятся множественные морфологические преобразования, состоящие в разметке текстов по частям речи и стемминге. Цель данных преобразований является оптимизация векторного пространства свойств объекта.
В следствии данных преобразований остаются лишь значимые слова – токены, определяющие весомые признаки принадлежности.
После необходимо было провекторизировать тексты.
Д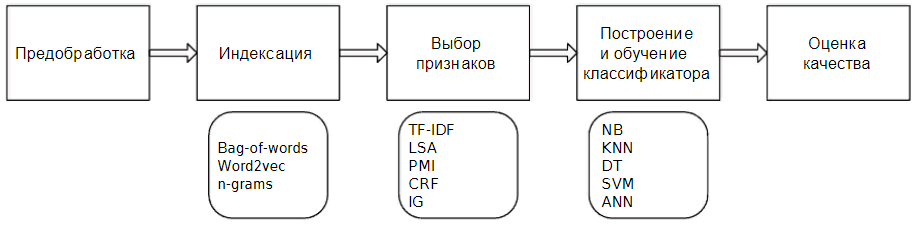
анная процедура представляет из себя преобразование текстовой информации в числовой вид (числовые векторы), что даст возможность проведения дальнейшей машинной обработки.
Рис. 3.1. Этапы классификации текста
Проанализировав множество алгоритмов и методов проведения классификации текстов, мы остановили свой выбор на четырёх методах векторизации.
При этом необходимо выполнить следующие шаги:
1) Перевод текста в набор числовых векторов, каждый из которых представляет частотную характеристику какого-либо из явлений;
2) Второй вариант предполагал создание матрицы слов, которых встречались во всех текстах не менее одного раза, после чего с помощью метрики TF-IDF происходило вычисление их частоты;
3) Перевод всех базисных слов из текста в семантические вектора, состоящие из некоторого количества чисел.
Суть первого способа обращения текстов в векторное пространство заключается в представлении каждого из них в виде характеристик относительной частотности явлений таких как: употребление союзов, глаголов и отглагольных наречий, сложных и простых предложений и др., характерных для каждого из социотипов характеристик.
На основе подобных маркеров можно, например, делать выводы о принадлежности автора к группе логиков или этиков.
Путём длительной обработки текстов был составлен набор признаков наиболее характеризующих социотипы, при котором сохраняется баланс между высокой точностью и достаточным временем работы классификатора.
В набор попали, к примеру, такие термины (ниже более детальное описание): знаки препинания, служебные части речи, униграммы, ласкательные суффиксы, средняя длина слова, средняя длина предложения, правильные глаголы, именные части речи.
Следующий способ обработки текстов носит название «мешок слов» - Bag-of-Words. Это наиболее простой и, в тоже время, наиболее стабильный алгоритм, предполагающий выделение наиболее часто встречающихся и значимых слов. Характерных каждому социотипу. При этом совершенно не учитывается порядок следования элементов (слов).
Другими словами, каждый документ – это вектор в многомерном пространстве, координаты которого соответствуют номерам слов, а значения координат – значениям весов.
Основные этапы подготовки (индексация и взвешивание признаков):
1) Создать массив слов, встречающихся в текстовом корпусе обучающей выборки;
2) определить показатель матрицы TF-IDF для каждого слова из обучающего корпуса текстов для каждого социотипа. Метрика TF-IDF выявляет частотность слов в тексте, беря за основу меру “уникальности” каждого из слов во всем корпусе:
ITF-IDF = ITF * IDF, где ITF – относительная частота слова в тексте, а IDF можно представить следующим образом:
WIDF =  , где n – размер корпуса, a – число текстов, в которых встречается данное слово.
, где n – размер корпуса, a – число текстов, в которых встречается данное слово.
Идея следующей методики базируется на идее представления слов в векторное пространство - «погружение» слов. При этом слова естественного языка посредством определённых моделей транспонируются в числовое векторное представление, причём, различной (произвольной) размерности. Среди различных критериев близости нами был выбран критерий отображения векторов на основе их семантической близости. То есть, задача векторизации слов заключается в том, чтобы векторы наиболее похожих в семантическом плане лексем расположились как можно близка друг к другу в некоем заданном n-мерном векторном пространстве.
Разработчиком данной методики является один из ведущих специалистов компании Google - Томас Миколов. Его идея состоит в том, чтобы располагать тем ближе друг к другу вектора слов, чем более схожи контексты, в которых они употребляются [25].
Для векторизации слов корпуса текстов по методике Т. Миколова, была обучена модель word2vec. Для её обучения пришлось воспользоваться готовыми векторными репрезентациями, представленными в 300-мерном пространстве для более, чем 150 000 русских слов, расположенными на ресурсе национального корпуса русского языка (http://rusvectores.org/ru).
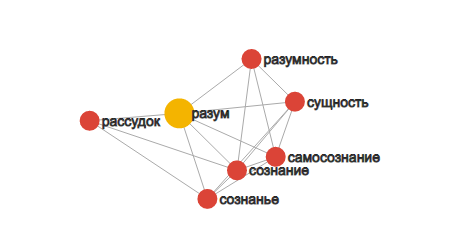
Рис. 3.2. Графическая интерпретация семантических связей
Альтернативный вариант, рассмотренный в нашем исследовании, уменьшения векторного пространства называется методом латентно-семантического анализа (LSA). Данный алгоритм выполняет сингулярное разложение матриц.
Векторные представления fastText в достаточной степени сходно с технологией, применяющейся в пространстве word2vec, за исключением некоторого отличия, которое состоит том, что fastText учитывает не только векторизованные слова, но и символьные n-граммы. Благодаря чему представляется возможным вычислить векторные представления неизвестных слов. Необходимо акцентировать внимание на том, что данная модель была обучена на корпусе слов русской Википедии.
Таким образом, в работе использовалось всего 4 способа векторного представления текста на русском языке (см. табл. 3.1).
Таблица 3.1
Алгоритмы векторизации
| Алгоритм | Характеристика |
| n-gram | представление в виде ряда статистических морфологических, синтаксических, экстралингвистических и некоторых других характеристик; |
| TF-IDF | разреженная матрица на основе технологии bag-of-words; |
| word2vec | модель погружений слов; |
| fastText | модель погружений слов. |
Далее необходимо было провести векторизацию текстов по данным моделям (алгоритмам) и определить эффективности при классификации, применяя так же различные методы классификации.
Перед преобразованием в векторный вид все текста были подвержены предварительной обработке:
Все символы были приведены к строчному представлению;
Все слова были очищены от лишних символов и отделены от знаков препинания;
Все слова были лемманизированы и подвержены грамматическому анализу с помощью блока морфологического анализатора.
В дополнении к этому, в случае 3 и 4 метода векторизации, тексты были очищены от стоп-слов - всех слов короче 3 символов.
Построение и обучение классификатора с помощью методов машинного обучения
Помимо непосредственно исследования способов и применения методик к автоматической классификации авторских текстов, важнейшим моментом данной работы является построение моделей, использующих в своей работе не один, а несколько методов исследования текстовой информации. И, соответственно, получения наиболее качественной методики определения соципотипов авторства. Учитывая большое разнообразие социотипов, и как следствие, наличие достаточно малого люфта между основными показателями речевых характеристик, интерес заключался в проведении сревнительного анализа в комбинации разных классификаторов и способов векторизации. В
данном исследовании классификация осуществлялась способами, которые можно поделить на две группы: 1) случайный лес, метод ближайших соседей, машина опорных векторов; 2) LSTM, GRU, полносвязная нейронная сеть. В первую группу вошли классифицированные методы - собственно методы машинного обучения, во вторую группу – нейронные сети различной архитектуры.
Перед использованием методов первой группы вся текстовая база (выборка) делится на две части: тестовую и тренировочную. После чего процесс проводится в два этапа: сначала классификатор “обучается” на тренировочной выборке, выделяя ключевые признаки и соотнося их числовые значения 16 социотипам авторов всех текстов заданной группы, а затем тестируется на тестовых текстах, отсутствующих в базе данных. В следствии чего, первый этап работы классификатора может быть назван тренировочным, а второй – тестовым.
Перед началом обучения значения на тестовой выборке, вкторизованные леммы, необходимо нормализовать, т.е. привести их весовой коэффициент к единому стандарту. В данном исследовании использовалась минимаксная нормализация. Это значит, что нормализация каждого параметра проводился по формуле V’ = (Vi - Vmin) / (Vmax - Vmin), где i – число всех параметров (в данном случае 13), Vi – значение текущего параметра, Vmax – максимальное значение данного параметра среди всех текстов, Vmin – минимальное значение данного параметра среди всех текстов. Результатом каждого преобразования становится “нормализованное”, т.е. принадлежащее промежутку [0,1] значение V’. [14]
Следующий шаг – проведение тестирования алгоритмов на второй части текстов, не вошедших в базу тестовых данных. Эта процедура включает вычисление значений различных параметров векторов, их нормализацию и, основанное на полученных данных, попытке предсказания принадлежности автора текста к одному из описанных социотипов. В данном алгоритме валидация работы алгоритма на “новых” текстах производилась по методу кросс-валидации:
320 текстов делятся на 16 частей по 20 текстов.
Каждая часть поочередно удаляется из базы данных, после чего программа заново обучается на измененной базе и выдвигает гипотезу о каждом из параметров социотипа автора: то есть, проводит бинарную классификацию по шкалам на соответствие одному из 16 социотипов.
Успешность установления психологического параметра в каждом случае определяется по метрике F1.
Модель выдвигает предположение о принадлежности автора текста заданному классу, сравнивая его с текстами из базы данных. Таким образом, задача классификации сводится к определению степени схожести числового вектора анализируемого текста с векторами текстов разных типов. В данном исследовании эта задача решена 3 методами машинного обучения:
Нейронные сети для классификации текстов
Концепция нейронных сетей основана на модели обработки информации человеческим мозгом. Искусственная нейронная сеть состоит из нейронов-неких абстрактных ячеек, которые могут принимать информацию в числовом виде, выполнять над ней определенные арифметические операции, нормализовывать и передавать полученные значения дальше. В общем случае нейроны в структуре сети объединяются в слои нескольких типов: нейроны входного слоя получают обучающие данные и передают их в неизменном виде дальше-на вход нейронов скрытых слоев. Именно на уровне скрытых слоев происходят основные вычисления, позволяющие выявить закономерности между данными, с помощью которых можно, например, осуществить их классификацию. В этом случае нейроны выходного слоя дают информацию о принадлежности объекта к определенному классу.
Существуют связи между нейронами разных слоев, которые имеют некоторый вес. Соответственно, значения самих нейронов при обучении умножаются на веса связей, и задача нейронной сети (как, собственно, и любой другой системы машинного обучения) сводится к определению наиболее удачной комбинации Весов, позволяющей добиться максимальной точности и минимальной погрешности классификатора. Если значение входных нейронов, т. е. обучающих данных, является постоянным, то веса выступают в качестве коэффициентов, значения которых изменяются на каждой итерации (один цикл обучения). Помимо коэффициентов по аналогии со свободным членом в других системах машинного обучения некоторые ячейки нейронной сети называются нейронами смещения и выполняют аналогичную функцию. Типы нейронных сетей различаются в зависимости от их архитектуры, которая определяется количеством, направлением, характером связей между нейронами разных слоев.
Мы использовали семантические сети 3-х типов:
1) многослойная полносвязная сеть прямого распространения (Naïve Base), в которой каждый нейрон соединен со всеми нейронами предыдущего слоя (Хайкин, 2006). Экспериментально были выбраны следующие параметры, необходимые для настройки и построения нейронной сети данного типа:
- 3 скрытых слоя;
количество нейронов в скрытых слоях, 300, 250 и 150;

(3.1)
- функции активации чередуются в скрытых слоях: ReLu (линейная ректификационная единица) по формуле f (x) = max (0, x); sigmoid (сигмоидальная функция активации), которая определяется формулой σ (x) = 1 / (1 + e^ (- x))
- 10 эпох обучения;
- 5 итераций на каждую эпоху;
- размер пакета (размер так называемого "batch size", т. е. единого обучающего набора, пакета данных) 24;
- loss (функция потери, т. е. функция вычисления ошибки классификации) - двоичная перекрестная энтропия. Если модель предсказывает значение p, тогда как истинное значение равно t, то двоичная перекрестная энтропия может быть вычислена по формуле-t*log(p) − (1−t)log (1-p)
- оптимизатор (функция оптимизации нейронной сети) - Adam (один из самых популярных встроенных оптимизаторов в keras).
2) рекуррентная нейронная сеть (LSTM), основанная на механизме обратного распространения ошибок - это означает, что информация, полученная на одном из скрытых слоев, в некоторой степени сохраняется и учитывается при расчетах на последующих слоях. Такие сети используются при обработке последовательностей, в которых важен порядок элементов. Примером такой последовательности является текст на естественном языке, который является объектом нашего исследования.
На самом деле, существует несколько типов рекуррентных нейронных сетей, и biLSTM и GRU используются в этом исследовании. Структура сети biLSTM (bidirectional long short – term memory-двунаправленная длительная краткосрочная память) усложняется следующим образом: во-первых, каждый нейрон характеризуется дополнительными фильтрами/клапанами ввода, забывания и вывода.
С помощью этих фильтров сеть учится определять, какая информация из предыдущих слоев хранится и передается дальше, ориентируясь на специальные параметры-постоянное и скрытое состояние каждой клетки, т. е. каждого нейрона. Внутреннее скрытое состояние вычисляется на основе текущего входного сигнала и предыдущего скрытого состояния. Структура хранения информации о скрытых состояниях ячеек делает такую сеть устойчивой к проблеме исчезающего градиента.
В нашем случае сеть (LSTM) также является двунаправленной – она учится учитывать информацию как с предыдущего, так и с последующего уровней, как бы производя обучение в обоих направлениях. Это реализуется с помощью двунаправленной оболочки для слоя lstm из библиотеки keras. В дополнение к двунаправленному рекуррентному слою сеть имеет следующие характеристики:
- длина входной последовательности равна 51 для частотных характеристик (по числу характеристик данных, перечисленных ранее) и 15091 для представления TF-IDF (по числу лексем в словаре);
- размер встраивания (глубина погружения) 128;
- 3 скрытых слоя с числом нейронов 256, 128, 64;
- отсев ("сбрасывание" некоторых случайных величин во время тренировки, чтобы предотвратить перетренированность) 0,3;
- 10 эпох обучения;
- 5 итераций на каждую эпоху;
- размер пакета (размер так называемого "batch size", т. е. единого обучающего набора, пакета данных) 24;

(3.2)
- loss (функция потери, т. е. функция вычисления ошибки классификации) - двоичная перекрестная энтропия. Если модель предсказывает значение p, тогда как истинное значение равно t, то двоичная перекрестная энтропия может быть вычислена по формулеt*log(p) − (1−t)log (1-p)
Рис. 3.3. Обобщенная схема сверхточной нейронной сети (LSTM сети)
3) сеть GRU (gated rucurrent unit – управляемый рекуррентный блок) имеет более простое устройство для реализации механизма запоминания, чем LSTM, и учится быстрее, но также устойчива к проблеме исчезающего градиента. В ячейке GRU есть только два клапана: сброс и обновление. управляемый блок обновления определяют, какую часть предыдущего сохраненного значения сохранить, а управляемый блок передачи определяют, как объединить предыдущую сетевую память с новым входом. Эта сеть задается параметрами, аналогичными параметрам LSTM, но она не является двунаправленной. Таким образом, при обучении учитывается только прямой порядок элементов.
Результаты классификации
Были построены модели классификаторов, основанные на использовании методов машинного обучения и иным методах.
Результаты классификации удобно представлены в двух таблицах, каждая из которых относится к одному бинарному психологическому параметру: интуиция-сенсорика или логика-этика. Размерность обеих таблиц составляет 4x5, столбцы представляют методы векторизации, а строки относятся к методам классификации, т. е. методам машинного обучения и типам архитектуры нейронных сетей, которые применялись в практической части исследования.
В таблицах жирным шрифтом выделены те методы классификации и методы векторного представления текстов, при которых достигаются наиболее высокие показатели точности. Последние, соответственно, представлены на пересечении столбцов с методами классификации и строк с методами векторизации.
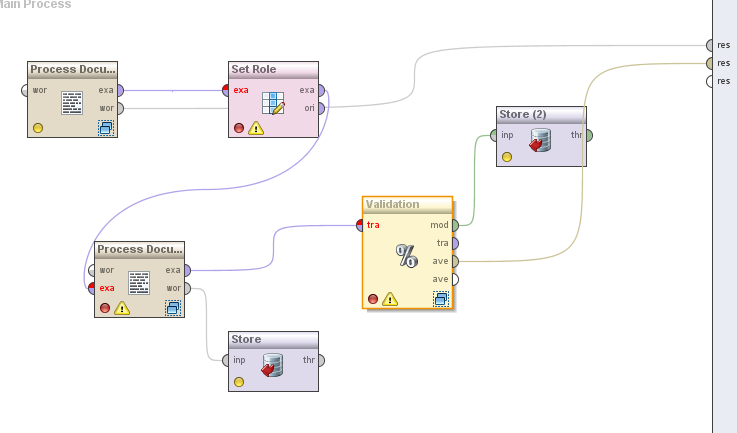
Рис 3.4. Алгоритм предобработки и векторизации текстов
Таблица 3.2
Частотные показатели распределения токенов в соответствии с правилами
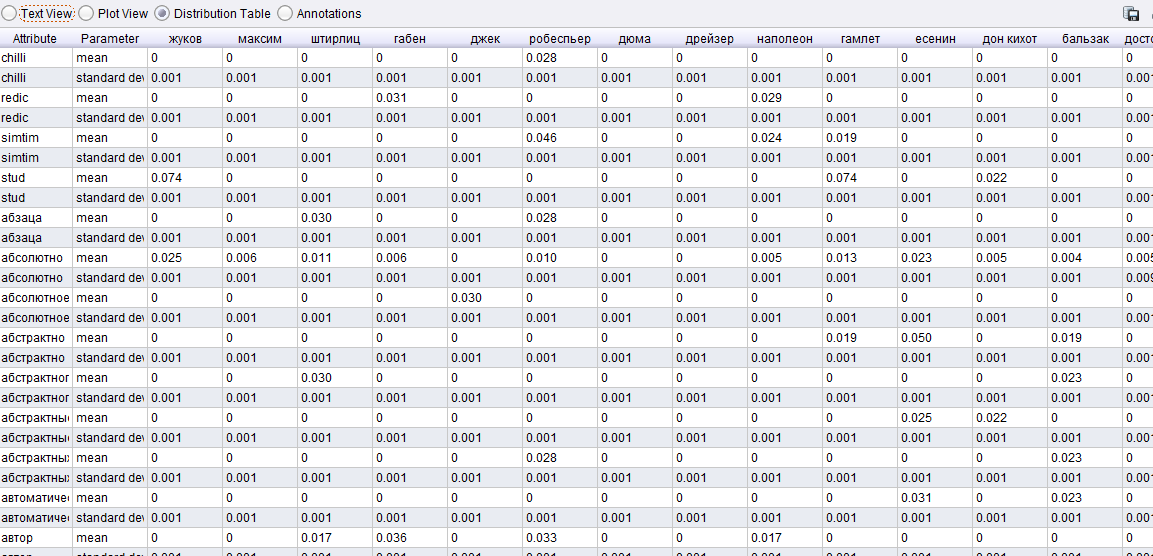
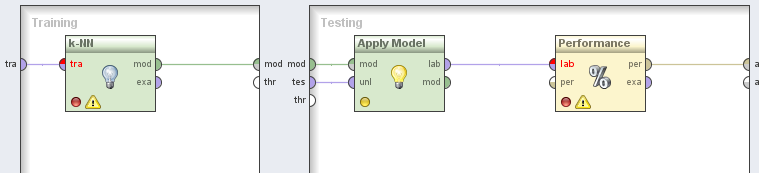
Рис. 3.5. Модели классификации на основе KNN
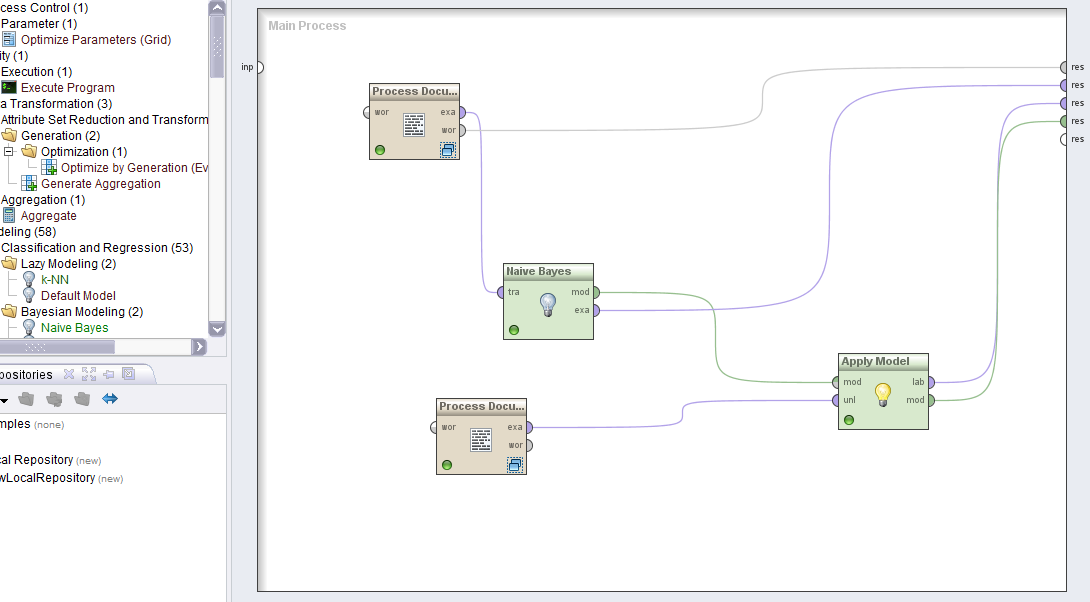
Рис. 3.6. Модели классификации на основе Naive Base
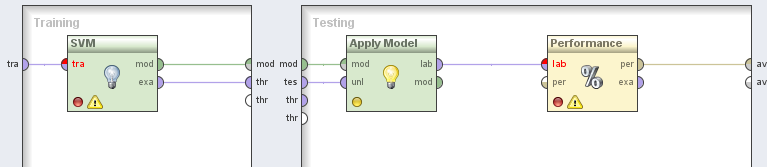
Рис. 3.7. Модели классификации на основе LSTM
Таблица 3.3
Результаты классификации по шкале логики-этики на основе методов машинного обучения
|
| TF-IDF | Частотные черты | Word2Vec | FastText |
| Naive Base | 0.53 | 0.46 |
|
|
| biLSTM | 0.43 | 0.66 | 0.52 | 0.54 |
| GRU | 0.4 | 0.61 | 0.41 | 0.38 |
Как видно из таблицы, наилучший результат в 66% достигается при использовании сети LSTM на материале текстов, преобразованных в числовые векторы, путем выделения 50 грамматических, синтаксических и экстралингвистических характеристик и подсчета их частотных индексов. Следующий результат 61% достигается при использовании сети GRU с тем же методом векторизации.
Вспомним полный перечень используемых признаков: ряды местоимений; сравнительные и переходные степени прилагательных и наречий; тип, наклонение и переходность глаголов; причастные залоги; композиционные и подчинительные союзы; знаки препинания; символические униграммы; улыбки; средняя длина слов и предложений; соотношение глагольной и именной частей речи; соотношение служебной и самостоятельной частей речи.
Таким образом, перечисленные признаки (или, по крайней мере, некоторые из них) обозначают такой психологический признак, как логическая или этическая направленность сознания.
Таблица 3.4
Результаты классификации по шкале интуиции-сенсорики на основе методов машинного обучения
|
| TF-IDF | Частотные черты | Word2Vec | FastText |
| Naive Base | 0.69 | 0.49 |
|
|
| biLSTM | 0.57 | 0.45 | 0.7 | 0.61 |
| GRU | 0.54 | 0.42 | 0.66 | 0.62 |
Наибольшая точность классификации - 72% - достигается при классификации по алгоритму случайного леса с векторизацией текста методом TF-IDF. Следующий результат в 70% показывает рекуррентная нейронная сеть LSTM с векторизацией по модели Word2Vec. Таким образом, печатать на шкале интуиции-сенсорики можно с большей точностью.
Известно, что метод Word2Vec позволяет сопоставить слово с некоторым контекстным вектором в многомерном семантическом пространстве. Таким образом, на выходе получаем матрицу распределения семантических полей текста. Можно сделать вывод, что это распределение маркирует признак интуиции-сенсорики.
Наконец, высокая точность метрики TF-IDF, ранжирующей слова по критерию информационной значимости, т. е. их редкости в корпусе и частотности в конкретном тексте, свидетельствует о корреляции этой психической функции с лексикой автора, соотношении редких и уникальных для корпуса в целом слов, используемых им в тексте. Конечно, в этом случае необходимо учитывать размеры собранного корпуса и его возможную непредставительность по указанному критерию.
При сравнении моделей были выявлены следующие достоинства и недостатки:
Таблица 4.1
Достоинства и недостатки наивного байесовского классификатора

Таблица 4.2.
Достоинства и недостатки нейронной сети
РАЗДЕЛ 4. ОХРАНА ТРУДА
При организации охраны труда на предприятиях в последнее время первое место занимает понятие "предотвращение опасности". В этом случае основным критерием оценки безопасности труда на рабочем месте становится критерий профессионального (производственного) риска. Управление производственными рисками становится основным механизмом в решении проблемы обеспечения безопасных условий труда.
Управление производственными рисками рассматривается как непрерывный процесс:
Рис. 4.1. Процесс управления рисками
Измерение физических факторов производственной среды на рабочих местах — один из элементов предотвращения опасности на рабочих местах.
Измеряют физические факторы производственной среды при проведении производственного контроля, а также при входном контроле осветительных устройств. Исследования проводит аккредитованная в качестве испытательной лаборатории в национальной системе аккредитации Служба охраны труда.
Основные светотехнические величины и единицы их измерения.
Значения освещенности количественно характеризуют влияние светового излучения на глаза человека. Обычно используются количественные измерения, такие как световой поток, сила света, освещенность, яркость поверхности, коэффициент отражения, коэффициент пропускания и поглощение.
Световой поток (F) - поток излучения, оцениваемый по его воздействию на человеческий глаз. На единицу - LUMEN (LM)
Сила света (I) - это пространственная плотность светового потока, которая определяется отношением светового потока F к коровьей (пространственной) α, в которых она распространяется ![]() . Для удельных сил света приняли Канделу (КД). Сплошной угол - это часть пространства сферы, ограниченная конусом, отраженным на поверхности сферы, с вершиной в центре. Стерадиан (SR) принимается за единицу телесного угла.
. Для удельных сил света приняли Канделу (КД). Сплошной угол - это часть пространства сферы, ограниченная конусом, отраженным на поверхности сферы, с вершиной в центре. Стерадиан (SR) принимается за единицу телесного угла.
Освещенность (E) – поверхностная плотность светового потока F. При равномерном распределении светового потока, перпендикулярного освещаемой поверхности S, освещенность ![]() . измеряется в люксах (лк).
. измеряется в люксах (лк).
Яркость поверхности (В) - плотность поверхности силы света и определяется как отношение силы света I в заданном направлении к проекции светящейся поверхности на плоскости, перпендикулярной направлению наблюдения ![]() , где ά - угол между отверстием к поверхности S и направлением к глазу. За единицу яркости Candela на м2 (кд/м2). Яркость света - это величина, которая непосредственно воспринимает человеческий глаз. Визуальные ощущения определяются яркостью освещенной поверхности в зависимости от ее цвета, шероховатости и других факторов. Чрезмерная яркость приводит к кратковременному ослеплению.
, где ά - угол между отверстием к поверхности S и направлением к глазу. За единицу яркости Candela на м2 (кд/м2). Яркость света - это величина, которая непосредственно воспринимает человеческий глаз. Визуальные ощущения определяются яркостью освещенной поверхности в зависимости от ее цвета, шероховатости и других факторов. Чрезмерная яркость приводит к кратковременному ослеплению.
Коэффициенты отражения ρ, пропускания τ и поглощения β поверхностей измеряются в % или долях единицы.
![]() ,
, ![]() ,
,![]() , где Fρ , Fτ, Fβ – соответственно отраженный, поглощенный и прошедший через поверхность световые потоки
, где Fρ , Fτ, Fβ – соответственно отраженный, поглощенный и прошедший через поверхность световые потоки
ФОН – поверхность. непосредственно примыкающая к объекту. Фон считается светлым при ρ0,4, средним при 0,4 ρ 0,2, темным при ρ
Контраст К – объекта наблюдения и фона определяется различием между их яркостями
К=(Во-Вф)/Вф, где Во, Вф – яркости объекта и фона
В настоящее время многие компании производят лампы общего освещения. Но при проведении производственного контроля часто приходится сталкиваться с тем, что заявленные производителем технические параметры ламп общего освещения не соответствуют требованиям, предъявляемым к освещению на этих рабочих местах. Соответственно, организации вынуждены приобретать новые светильники, что является дополнительной платой - за покупку светильников, за переустановку.
Освещение рабочего места является важным фактором в создании нормальных условий труда. Плохое освещение может исказить информацию, которую человек получает через зрение. Кроме того, он утомляет не только зрение, но и вызывает утомление организма в целом, негативно влияет на состояние центральной нервной системы.
Неправильное освещение может привести к травмам на производстве.
Освещение влияет на производительность и качество продукции. Так, при выполнении точной Сборки увеличение света с 50 до 1000 люкс позволяет увеличить производительность труда на 25%, даже при выполнении работы низкой точности, низкой глазной колеи, увеличение освещенности рабочей станции-сотни увеличивает производительность труда на 2-3% оптической областью спектра называется часть электромагнитного спектра с длиной волны = 10–340 нм, она делится на:
инфракрасное излучение (= 340–770 нм). Проявляется в основном в тепловом воздействии;
видимое излучение (= 770–380 нм). В зависимости от длины волны вызывает у человека различные световые и цветовые ощущения — от фиолетового (= 400 нм) до красного (= 750 нм).
ультрафиолетовое излучение (= 380–10 нм). УФ-излучение оказывает биологически положительное воздействие на организм человека, вызывая загар, при высокой интенсивности способно привести к ожогу кожи, глаз. УФ-излучение возникает при электро- и газовой сварке, при работе кварцевых ламп, электрической дуги высокой интенсивности, лазерных установок.
По данным СанПиНа 2.2.2/2.4.1340-03 " Гигиенические требования к персональным электронным вычислительным машинам и организации работы. Санитарно-эпидемиологические правила и стандарты "к освещению рабочих мест, оборудованных ПК, предъявляются следующие требования:
1. Искусственное освещение в помещениях для работы ПК должно осуществляться с помощью общей единой системы освещения.
2. Освещенность поверхности стола в зоне размещения рабочего документа должна составлять 300-500 люкс. Освещение не должно создавать бликов на поверхности экрана. Освещенность поверхности экрана не должна превышать 300 люкс.
3. Прямые блики от источников света должны быть ограничены. Яркость светящихся поверхностей (окон, ламп и др.) в поле зрения не должно превышать 200 кд / м2.
4. Необходимо ограничить отраженные блики на рабочих поверхностях (экран, стол, клавиатура и др.) за счет правильного подбора типов осветительных приборов и расположения рабочих мест относительно источников естественного и искусственного освещения. Яркость бликов на экране ПК не должна превышать 40 кд / м2, яркость потолка не должна превышать 200 кд / м2.
5. Показатель ослепленности для источников общего искусственного освещения в производственных помещениях — не более 20. Показатель дискомфорта в административно-общественных помещениях — не более 40, в дошкольных и учебных помещениях — не более 15.
6. Яркость светильников общего освещения в зоне углов излучения от 50 до 90˚ с вертикалью в продольной и поперечной плоскостях должна составлять не более 200 кд/м2, защитный угол светильников должен быть не менее 40˚.
7. Светильники местного освещения должны иметь не просвечивающий отражатель с защитным углом не менее 40˚.
8. Следует ограничивать неравномерность распределения яркости в поле зрения пользователя ПЭВМ. Соотношение яркости между рабочими поверхностями не должно превышать 3:1…5:1, а между рабочими поверхностями и поверхностями стен и оборудования — 10:1.
9. В качестве источников света при искусственном освещении следует применять преимущественно люминесцентные лампы типа ЛБ и компактные люминесцентные лампы (КЛЛ). При устройстве отраженного освещения в производственных и административно-общественных помещениях допускается применять металлогалогенные лампы. В светильниках местного освещения допускается применение ламп накаливания, в том числе галогенные.
10. Для освещения помещений с ПЭВМ следует применять светильники с зеркальными параболическими решетками, укомплектованными электронными пускорегулирующими аппаратами (ЭПРА). Допускается использование многоламповых светильников с электромагнитными пускорегулирующими аппаратами (ЭПРА), состоящими из равного числа опережающих и отстающих ветвей.
5. Индекс ослепления для источников Общего искусственного освещения в промышленных помещениях - не более 20. Индекс дискомфорта в административных и общественных помещениях - не более 40, в дошкольных и образовательных помещениях - не более 15.
6. Яркость ламп общего освещения в зоне углов излучения от 50 до 90 с вертикалью в продольной и поперечной плоскостях должна составлять не более 200 КД/м2, защитный угол ламп должен составлять не менее 40.
7. Местные осветительные приборы должны иметь непрозрачный отражатель с защитным углом не менее 40.
8. Необходимо ограничить неравномерное распределение яркости в поле зрения пользователя ПК. Соотношение яркости между рабочими поверхностями не должно превышать 3: 1... 5: 1, а между рабочими поверхностями и поверхностями стен и оборудования - 10:1.
9. В качестве источников света при искусственном освещении следует использовать в основном люминесцентные лампы типа LB и компактные люминесцентные лампы (CFL). При устройстве отраженного освещения в производственных и административных и общественных помещениях допускается применение металлогалогенных ламп. В лампах местного освещения допускается применение ламп накаливания, в том числе галогенных.
10. Для освещения помещений с ПК необходимо применять лампы с зеркальными параболическими решетками, завершенными электронными регулировочными устройствами запуска (ЭПРА). Допускается использование многоламповых светильников с электромагнитными устройствами управления запуском (ЭПРА), состоящими из равного количества ведущих и ведомых ветвей.
При отсутствии ламп из ЭПРА лампы многокамерных ламп или смежные лампы общего освещения включаются на разные фазы трехфазной сети.
11. Общее освещение при использовании люминесцентных светильников должно быть выполнено в виде сплошных или прерывистых линий светильников, расположенных со стороны рабочих мест, параллельно линии зрения пользователя при рядном расположении терминалов видеодисплея. Когда компьютеры расположены по периметру, линии светильника должны располагаться над рабочим столом ближе к краю рабочего стола, обращенному к оператору.
12. Коэффициент запаса (Кз) для осветительных установок общего освещения должен приниматься равным 1,4.
Рис. 4.2. Меры безопасности при работе на ПЭВМ приведены
При проведении измерений используется прибор комбинированный ТКА-ПКМ (09). Погрешность измерений — 10 %. Характеристики наиболее часто используемых светильников сведены в таблицу.



Рис. 4.3. Характеристики наиболее часто используемых светильников
При анализе результатов измерений во время входного контроля ламп установлено следующее:
1. Люминесцентная лампа, имеет маркировку на внутренней стороне корпуса LPO-46-2×36 712UHL4, электронный PRA (ElectronicBallast) PHILIPS EB-C 236 TL-D 220-240.
Для измерений использовались лампы FL36W/635.
Основываясь на фактическом уровне пульсации (5,3%), лампа может использоваться на рабочих местах, не оборудованных ПК. Одного светильника недостаточно, чтобы соответствовать параметру освещения.
2. Люминесцентный светильник, маркированный на внутренней стороне корпуса LPO01-2×36-012 "Кристалл", ксенон, Россия, электронно-лучевой PRA (ElectronicBallast) LC 2×36 T812-C.
Для измерений использовались лампы FL36W/635.
Основываясь на фактическом уровне пульсации (3,4%), лампу можно использовать на рабочих местах с ПК. Одного светильника недостаточно, чтобы соответствовать параметру освещенности.
3. Люминесцентная лампа, имеет маркировку на внутренней стороне корпуса стандарт 236-27 УХЛ 4, на упаковке указано производитель-тд ООО "ТРИЛЮКС", Россия, электронный пра (ElectronicBallast) GeneralG-EB236 220-240.
Для измерений использовались лампы FL36W/635.
Основываясь на фактическом уровне пульсации (5,9%), лампа может использоваться на рабочих местах, не оборудованных ПК. Одного светильника (до 200 люкс) достаточно, чтобы соответствовать параметру освещения.
4. Светодиодная лампа пыле-и влагостойкая, имеет этикетку на упаковке JazzwayPWP-1200 2X20W 6500KIP65 230V/50Hz, OPALTEK (GK), Китай.
Для измерений использовались светодиодные лампы jazzwayC0714.
Основанный на фактическом уровне пульсации (3,0%), лампу можно использовать в рабочих местах с ПК. Одного светильника недостаточно, чтобы соответствовать параметру освещенности.
5. Светодиодная лампа пыле-и влагостойкая, имеет этикетку на упаковке JazzwayPWP-1200-SMD 40W 6500KIP65 230V/50Hz, OPALTEK (GK), Китай. В соответствии с данной информацией в светильниках применены СМД 2835 светодиоды.
Основываясь на фактическом уровне пульсации (6,0%), лампа может использоваться на рабочих местах, не оборудованных ПК. Одного светильника (до 200 люкс) достаточно, чтобы соответствовать параметру освещения.
6. Люминесцентная лампа, маркированная на внутренней стороне корпуса и на упаковке ARCTIC 236 1069002410 (SAN / SNC) (2) HF ООО "Завод светотехнических технологий", Россия, electronic PRA (ElectronicBallast) HelvarEL 2×36es-h.
Для измерений использовались лампы FL36W/635.
Основанный на фактическом уровне пульсации (2.9%), лампу можно использовать в рабочих местах с ПК. Одного светильника недостаточно, чтобы соответствовать параметру освещенности.
7. Светодиодная лампа, маркированная на упаковке JazzwayPPL 595/4-72 36W 3250Lm 4000K, OPALTEK (GK), Китай. Согласно вышеуказанной информации, в светильниках используются светодиоды SMD 5630 Epistar.
Основанный на фактическом уровне пульсации (3,0%), лампу можно использовать в рабочих местах с ПК. Для того чтобы соответствовать освещенности одной лампы на рабочем месте с ПК недостаточно.
Следует отметить, что при освещении рабочих мест люминесцентные источники света имеют серьезное преимущество перед светодиодными. Светодиодный светильник состоит из большого количества очень маленьких и очень ярких источников света, улавливаемых периферийным зрением рабочего. Постоянное воздействие такого света (в течение рабочего дня) может привести к определенной доле слепоты работника и усталости глаз. Это было подтверждено в процессе опытной эксплуатации таких ламп службой охраны труда.
ЗАКЛЮЧЕНИЕ
По результатам проведенного исследования можно сделать вывод, что психотип, в соответствии с теоретическими обоснованиями, коррелирует с языковыми характеристиками человека, что подтвердилось и практически было подтверждено, что авторские тексты разных психотипов отличаются ярко выраженными языковыми и речевыми признаками. Исходя из результатов анализа, проявляется чётко выраженное влияние наиболее развитой дихотомии на структуру речи и письма индивида.
Стоит учитывать тот факт, что, например, частотный анализ был преимущественно морфологического уровня. Известно, что он гораздо менее индивидуализирован, чем лексический, семантический и синтаксический. Таким образом, основные перспективы совершенствования данного исследования заключаются в выборе более репрезентативных признаков для классификации. Стоит обратить внимание на равномерность их распределения, выделив одинаковое количество ярких признаков развития каждой функции.
Юнговская модель классификации накладывает определённые трудности в достижении высоких показателей классификации. Это обусловлено требованием к накоплению большого и разнообразного массива речевых характеристик. Таким образом, более детальная классификация может повлиять на точность результатов в лучшую сторону, если отобрать достаточное количество репрезентативных речевых характеристик для определения психотипа.
Важным ограничением является неопределенность юнгианской модели психики и не стопроцентная валидность тестов-опросников, направленных на определение психотипа. Разработка и применение более точных методов классификации по типам Юнга, относящихся к области психологии, позволит качественно улучшить работу классификаторов. При использовании модели на основе «мешка слов» и обучении нейронных сетей необходимо кратное увеличение репрезентативной выборки, что даст прирост точности классификации.
В ходе исследования были решены следующие задачи:
1) Проанализированы основные психологические типологии, в частности те, авторы которых достаточно подробно описывают лингвистический аспект проявления психологических характеристик личности. Определена классификация, наиболее подходящая для проведения практического исследования феномена связи между психологическими и языковыми особенностями личности. Такова была классическая типология К. Г. Юнга.
2) Собрана база данных речевого материала различных психотипов, каждый текст которой подвергался автоматическому анализу и преобразовывался различными способами в числовой вектор, состоящий из частотных значений различных языковых признаков или показателей некоторых абстрактных семантических измерений, кодирующих слова. Все значения были нормализованы для корректной постобработки.
3) Собраны и протестированы различные классификаторы текстов по типологии Юнга. С их помощью был проведен практический анализ текстов обладателей различных психотипов, который показал, что речевое оформление действительно может отличаться в зависимости от психических особенностей, и в этом случае каждый отличительный признак имеет определенные вербальные корреляты.
4) Установлена точность различных алгоритмов классификации, определены наиболее эффективные из них. Кроме того, делаются предположения о факторах, оказавших негативное влияние на результаты работы классификаторов.
5) Сделаны выводы о том, какие показатели маркируют реализацию Юнговских психических функций в речи и, соответственно, какие признаки могут быть использованы для классификации по различным функциональным шкалам психотипов.
Цель исследования достигнута – классификация по психотипам с использованием методов машинного обучения на основе анализа авторских текстов показывает свою эффективность.
Для совершенствования самого алгоритма и, как следствие, более точной классификации необходимо предпринять несколько важных шагов: существенно расширить базу текстов; произвести тщательный отбор релевантных признаков для исследования; расширить методологическую базу до более точных языковых моделей в сочетании с новыми, более тонкими лексическими и синтаксическими признаками.
СПИСОК ЛИТЕРАТУРЫ
Koppel M., Akiva N., Alshech E., Bar K. Automatically Classifying
Documents by Ideological and Organizational Affiliation. In Proccedings of
IEEE Intelligence and Security Informatics, Dallas TX, June 2009.
Koppel M., Akiva N., Dagan I. A Corpus-Independent Feature Set for StyleBased Text Categorization. In Proceedings of IJCAI'03 Workshop on
Computational Approaches to Style Analysis and Synthesis, Acapulco,
Mexico, 2003.
Koppel M., Argamon S., Shimoni A, Automatically categorizing written
texts by author gender. Literary and Linguistic Computing, 17(4): 401-412,
November 2002.
Stamatatos E. Ensemble-based author identification using character n-grams. In Proceedings of the 3rd International Workshop on Text-Based
Information Retrieval, 41–46, 2006.
Schler J., Koppel M., Argamon S., Pennebaker J. Effects of Age and Gender on Blogging. In Procceedings of AAAI Spring Symposium on
Computational Approaches for Analyzing Weblogs, March 2006.
Sebastiani F., Machine learning in automated text categorization. ACM
Computing Surveys, 34(1):1–47, 2002.
Stamatatos E. Ensemble-based author identification using character n-grams. In Proceedings of the 3rd International Workshop on Text-Based
Information Retrieval, 41–46, 2006.
Stamatatos E., Survey of Modern Authorship Attribution Methods. Journal of the American Society for Information Science and Technology, Wiley,
60(3): 538-556, 2009.
Topic modeling [Электронный ресурс] – Режим доступа: http://blog.biolab.si
http://retrans.ru.
http://metafraz.com.
http://www.cs.uvm.edu/~icdm/algorithms/10Algorithms-08.pdf.
http://ruscorpora.ru.
Белоногов Г. Г., Калинин Ю. П., Хорошилов А. А. Компьютерная лингвистика и перспективные информационные технологии. Теория и практика построения систем автоматической обработки текстовой информации. – Москва: Информационноиздательское агентство "Русский мир", 2004.
Карасик В.И. Языковой круг: личность, концепты, дискурс / В.И. Карасик. Волгоград: Перемена, 2002. 477 с.
Караулов Ю.Н. Русский язык и языковая личность. Изд. 7-е / Ю.Н. Караулов. М.: Изд-во ЛКИ, 2010. 264 с.
Мартыненко Г.Я., Многомерный синтаксический анализ
художественной прозы. Структурная и прикладная лингвистика, Л,
Изд-во ЛГУ, Вып.2, c.58-72, 1983.
Мартынюк А.П. Прагматические особенности текста в зависимости от пола автора, Вестник Харьковского университета, №322, c. 56-60, 1988.
Минин М.Ю., Бидюков П.И. Применение аппарата нечеткой логики для анализа психологических типов на основе базиса Юнга при принятии кадровых решений. ААЭКС, №1(13), 2004, Моделирование объектов и систем управления.
Морозов Н.А. Лингвистические спектры: средство для отличения
плагиатов от истинных произведений того или иного известного автора. Стилеметрический этюд, Известия отд. русского языка и
словесности Имп.акад.наук, Т.20, Кн.4, 1915.
Национальный Корпус Русского языка. Электронный ресурс.
Ощепкова Е. С. Идентификация пола автора по письменному тексту
(Лексико-грамматический аспект). Дисс. канд. филол. наук, М., 2003.
Родионова Е.С. Методы атрибуции художественных текстов.
Структурная и прикладная лингвистика, Вып. 7, Межвуз. сб., Под ред. А.С. Герда, СПб, Изд-во С.-Петерб. Ун-та, c. 118-127, 2008.
Севбо И.П. Графическое представление синтаксических структур и
стилистическая диагностика, Киев, 1981.
Сиротинина О.Б., Гольдин В.Е. Речевая коммуникация и ее изучение.
Проблемы речевой коммуникации, Межвуз. сб. науч. тр., Саратов, c. 3-
5, 2000.
Тарасов Г.В. Примеры нечетких множеств для формирования психологического портрета личности. Прикладная информатика №4-28. 2010г.
Фоменко В.П., Фоменко Т.Г. Авторский инвариант русских
литературных текстов. Предисловие А.Т. Фоменко. Фоменко А.Т.
Новая хронология Греции: Античность в средневековье, Т. 2., М, Издво МГУ, c.768-820, 1996.
Хмелѐв Д.В. Распознавание автора текста с использованием цепей А.А. Маркова. Вестн. МГУ, Сер. 9, Филология, N02, c.115-126, 2000.
Хьетсо Г., Густавссон С., Бекман Б., Гил С. «Кто написал «Тихий Дон», М., “Книга”, 1989.
Шкуратова И.П. Речь как средство самовыражения личности. СевероКавказский психологический вестник, 2009.
Юнг К. Психологические типы под общей редакцией / К. Юнг, под ред. В. Зеленского. М.: Прогресс-Универс, 1995. 761 с.
Приложение А
СЕМАНТИЧЕСКОЕ ЯДРО ПРИ АНАЛИЗЕ ТЕКСТОВ С САЙТА SOCIOFORUM.SU
| Фраза/слово | Количество | Частота, % | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Бальзак | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Габен | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Гамлет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Гюго | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Джек Лондон | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Дон Кихот | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Дрейзер | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Дюма | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Есенин | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Жуков | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Наполеон | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Робеспьер | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Штирлиц | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Максим Горький | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Достоевский | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Гексли | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||








© 2023, Шаповалов Иосиф Леонидович 90 0
Рекомендуем курсы ПК и ППК для учителей






Похожие файлы
Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!
Полезное для учителя

Реализация образовательных программ осуществляется с применением исключительно электронного обучения и ДОТ



