







© 2021 124 0


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Преобразование информации в данные. Данные типы, структуры и управление. Понятие и основные типы структур данных /9/
Категория:
Прочее
14.12.2021 17:24

Просмотр содержимого документа
«Преобразование информации в данные. Данные типы, структуры и управление. Понятие и основные типы структур данных /9/»
Понятие и основные типы структур данных
Структура данных (англ. data structure) — программная единица, позволяющая хранить и обрабатывать множество однотипных и/или логически связанных данных в вычислительной технике. Для добавления, поиска, изменения и удаления данных структура данных предоставляет некоторый набор функций, составляющих её интерфейс.
Термин «структура данных» может иметь несколько близких, но, тем не менее, различных значения:
Абстрактный тип данных;
Реализация какого-либо абстрактного типа данных;
Экземпляр типа данных, например, конкретный список;
В контексте функционального программирования — уникальная единица (англ. unique identity), сохраняющаяся при изменениях. О ней неформально говорят, как об одной структуре данных, несмотря на возможное наличие различных версий
Структуры данных — это контейнеры, которые хранят данные в определенном формате. Этот специфический формат придает структуре данных определенные качества, которые отличают ее от других структур и делают ее пригодной (или напротив, неподходящей) для тех или иных сценариев использования.
Рассмотрим некоторые из наиболее важных структур данных, которые помогут создавать эффективные решения.
Массивы
Массивы — одна из самых простых и часто применяемых структур данных. Такие структуры данных, как очереди и стеки, основаны на массивах и связанных списках (которые мы рассмотрим чуть позже).
Каждому элементу в массиве присваивается положительное целое число, которое обозначает положение элемента. Это число называется индексом. В большинстве языков программирования индексы начинаются с нуля. Эта концепция называется нумерацией на основе нуля.
Существует два типа массивов: одномерные и многомерные. Первые представляют собой простейшие линейные структуры, а вторые — вложенные и включают другие массивы.
Основные операции с массивами
Get — получить элемент массива по заданному индексу.
Insert — вставить элемент массива по заданному индексу.
Length — получить количество элементов в заданном массиве.
Delete — удалить элемент массива по заданному индексу. Может быть выполнено либо путем установки значения undefined, либо путем копирования элементов массива, за исключением удаляемого, в новый массив.
Update — обновление значения элемента массива по заданному индексу.
Traverse — проход цикла через массив для выполнения функций над элементами массива.
Search — поиск определенного элемента в заданном массиве с помощью выбранного алгоритма.
Применение массивов
Представляют собой строительные блоки более сложных структур данных, таких как стеки, очереди и т.д.
Подходят для хранения несложных связанных данных благодаря простоте использования.
Используются для различных алгоритмов сортировки, таких как сортировка вставок, сортировка пузырьком и т.д.
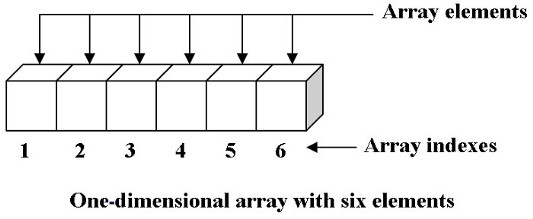 Одномерный массив
Одномерный массив
 Многомерный массив
Многомерный массив
Связанный список (Linked List)
Связанный список — это набор элементов, называемых узлами, в линейной последовательной структуре. Узел — простой объект с двумя свойствами. Это переменные для хранения данных и адреса памяти следующего узла в списке. Поэтому узел знает только о том, какие данные он содержит и кто его сосед. Это позволяет создавать связанные списки, в которых каждый узел связан с другим.
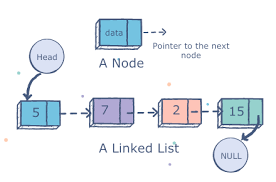
Существует несколько типов связанных списков.
Односвязный. Обход элементов может выполняться только в прямом направлении.
Двусвязный. Обход элементов может выполняться как в прямом, так и в обратном направлениях. Узлы включают дополнительный указатель, известный как prev, указывающий на предыдущий узел.
Круговые связанные. Это связанные списки, в которых предыдущий (prev) указатель “головы” указывает на “хвост”, а следующий указатель “хвоста” указывает на “голову”.
Основные операции со связанными списками
Insertion — добавление узла в список. Это может быть сделано на основе требуемого местоположения, такого как голова, хвост или где-то посередине.
Delete — удаление узла в начале списка или на основе заданного ключа.
Display — отображение полного списка.
Search — поиск узла в данном связанном списке.
Update — обновление значения узла в заданном ключе.
Применение связанных списков
В качестве строительных блоков сложных структур данных, таких как очереди, стеки и некоторые типы графиков.
В слайд-шоу изображений, поскольку изображения идут строго друг за другом.
В динамических структурах для выделения памяти.
В операционных системах для легкого переключения вкладок.
Стек
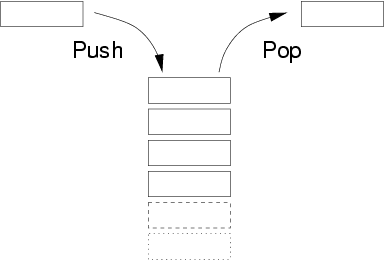
Стек — линейная структура данных, которая создается на основе массивов или связанных списков. Стек следует принципу Last-In-First-Out (LIFO, “первым на вход — последним на выход”), т.е. последний элемент, вошедший в стек, будет первым, кто покинет его. Причина, по которой эта структура называется стеком, в том, что ее можно визуализировать как стопку книг на столе (по-английски stack).
Основные операции со стеком
Push — вставка элемента в верхнюю часть стека.
Pop — удаление элемента из верхней части стека с возвращением элемента.
Peek — просмотр элемента в верхней части стека.
isEmpty — проверка пустоты стека.
Применение стеков
В истории навигации браузера.
Для реализации рекурсии.
При выделении памяти на основе стека.
Очередь
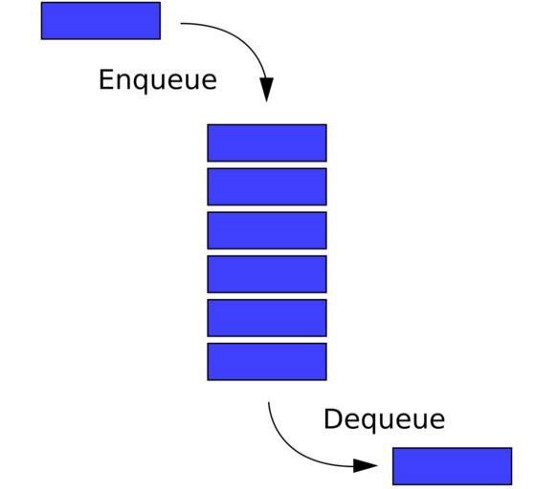
Как и стек, очередь — это еще один тип линейной структуры данных, основанной либо на массивах, либо на связанных списках. Очереди отличаются от стеков тем, что они основаны на принципе First-In-First-Out (FIFO, “первым на вход — первым на выход”), где элемент, который входит в очередь первым, и покинет ее первым.
Реальная аналогия структуры данных “очереди” — это очередь людей, ожидающих покупки билета в кино.
Основные операции с очередями
Enqueue — вставка элемента в конец очереди.
Dequeue — удаление элемента из передней части очереди.
Top/Peek — возвращает элемент из передней части очереди без удаления.
isEmpty — проверка содержимого очереди.
Применение очередей
Обслуживание нескольких запросов на одном общем ресурсе.
Управление потоками в многопоточных средах.
Балансировка нагрузки.
Граф
Граф — это структура данных, представляющая собой взаимосвязь узлов, которые также называются вершинами. Пара (x,y) называется ребром. Это указывает на то, что вершина x соединена с вершиной y. Ребро может указывать на вес/стоимость, то есть стоимость прохождения по пути между двумя вершинами.
Ключевые термины
Размер — количество ребер в графике.
Порядок — количество вершин в графе.
Смежность — случай, когда два узла соединены одним и тем же ребром.
Петля — вершина, соединенная ребром сама с собой.
Изолированная вершина — вершина, которая не связана с другими вершинами.
Графы делятся на два типа. Они различаются главным образом по направлениям пути между двумя вершинами.
Ориентированные графы: все ребра имеют направления, указывающие начальную и конечную точки (вершины).
Неориентированные графы: ребра не имеют направлений, которые позволяют обходам происходить с любого направления.
Распространенные алгоритмы обхода графов
Поиск в ширину (BFS) — метод поиска кратчайшего пути в графе, основанный на вершинах.
Поиск в глубину (DFS) — метод, основанный на ребрах.
Основные операции с графами
Add vertex: добавить вершину в граф.
Add edge: добавить ребро между двумя вершинами.
Display: отобразить вершину.
Total cost of traversal: найти общую стоимость пути обхода.
Применение графов
Для представления потоковых вычислений.
При распределении ресурсов операционной системой.
Реализация алгоритмов поиска друзей в Facebook.
Расчет кратчайшего пути между двумя локациями (Google Maps).
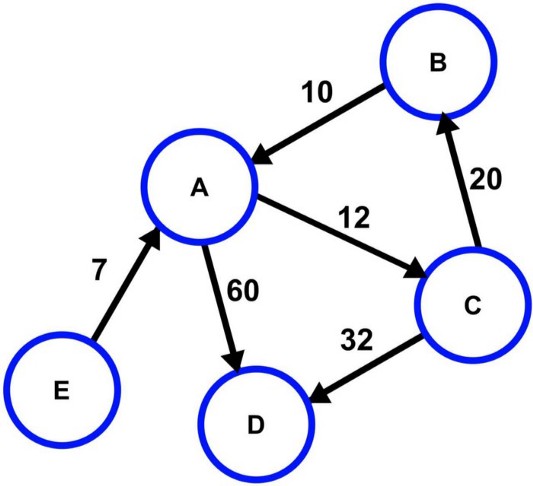
Ориентированный граф со стоимостью
Дерево
Дерево — это иерархическая структура данных, состоящая из вершин (узлов) и ребер, которые их соединяют. Деревья часто используются в системах искусственного интеллекта и сложных алгоритмах, поскольку обеспечивают эффективный подход к решению проблем. Дерево — это особый тип графа, который не содержит циклов. Некоторые утверждают, что деревья полностью отличаются от графов, но эти аргументы субъективны.
Существует несколько типов деревьев.
N-арное дерево.
Сбалансированное дерево.
Бинарное дерево.
Бинарное дерево поиска (BST).
Дерево AVL.
Красно-черное дерево.
2-3-дерево.
BST — самые распространенные типы деревьев.
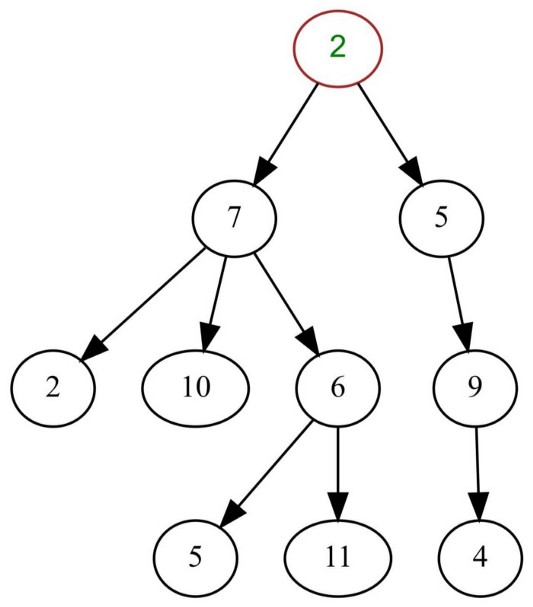
Простое дерево
Основные операции с BST
Insert — вставка элемента в дерево.
Search — поиск элемента в дереве.
PreorderTraversal — обход дерева прямым способом.
InorderTraversal — обход дерева центрированным способом.
PostorderTraversal — обход дерева обратным способом.
Применение деревьев
Представление организации.
Представление компьютерной файловой системы.
Представление химической формулы.
В деревьях принятия решений.
Внутри JVM (Java Virtual Machine) для хранения объектов Java.
Хэш-таблица
Хэш-таблица хранит данные в парах ключ-значение. Это означает, что каждый ключ в хэш-таблице имеет некое значение, связанное с ним. Такая простая компоновка обеспечивает эффективность хэш-таблиц, независимо от их размера, при работе с данными.
Хэш-таблицы похожи на обычное хранилище данных с парой ключ-значение, однако их отличает способ генерации ключей. Они создаются с помощью специального процесса, называемого хэшированием.
Хеширование (хэш-функция)
Хэширование — это процесс, который с помощью хэш-функции преобразует ключ для получения хэшированного ключа. Эта хэш-функция определяет индекс таблицы или структуры, в которых должно храниться значение.
h(k) = k % m
h — хэш-функция.
k — ключ, из которого должно быть определено хэш-значение.
m — размер хэш-таблицы.
Например, рассмотрим использование хэш-функции k%17. Если исходный ключ равен 20, то хэшированный будет 20%17=3. Значение будет храниться в хэш-таблице под индексом 3.
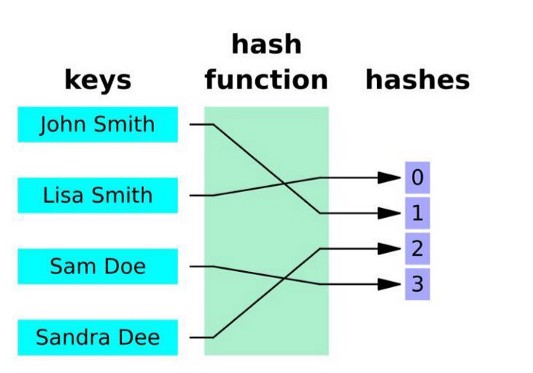
Хэш-функция для ключей
Зачем нужен хэш?
Некоторые задаются вопросом, зачем проходить через дополнительный процесс хэширования, когда можно просто сопоставить значения непосредственно с ключом. Хотя прямое сопоставление несложно, оно может оказаться неэффективным при работе с большим набором данных. С помощью хеширования можно достичь почти постоянного времени.
Коллизии
Поскольку для преобразования ключей используется общая хэш-функция, существует вероятность коллизий. Рассмотрим приведенный ниже пример с учетом хэш-функции k%17.
Когда k = 18, h(18) = 18%17 = 1.
При k = 20, h(20) = 20%17 = 3.
При k = 35, h(35) = 35%17 = 1.
Когда ключи равняются 18 и 35, происходит коллизия, поскольку они направляются к индексу 1.
Коллизии можно разрешить с помощью таких стратегий, как раздельная цепочка и открытая адресация.
Основные операции с хэш-таблицами
Search — поиск элемента в хэш-таблице.
Insert — вставка элемента в хэш-таблицу.
Delete — удаление элемента из хэш-таблицы.
Применение хэш -таблиц
В индексации баз данных.
При проверке орфографии.
При реализации заданной структуры данных.
В кэше.






Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!
Полезное для учителя

Реализация образовательных программ осуществляется с применением исключительно электронного обучения и ДОТ

