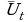
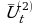
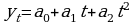
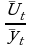
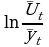
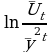








© 2021, Файзуллина Айгуль Гинатулловна 187 0


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Была в сети 02.06.2023 11:32

Файзуллина Айгуль Гинатулловна
Специализация
Теоретические основы статистического анализа. Понятие временного ряда
Категория:
Прочее
20.10.2021 10:48

Просмотр содержимого документа
«Теоретические основы статистического анализа. Понятие временного ряда»
Теоретические основы статистического анализа. Понятие временного ряда
Объектом исследования в прикладной статистике являются статистические данные, полученные в результате наблюдений или экспериментов. Статистические данные – это совокупность объектов (наблюдений, случаев) и признаков (переменных), их характеризующих.
Переменные – это величины, которые в результате измерения могут принимать различные значения.
Независимые переменные – это переменные, значения которых в процессе эксперимента можно изменять, а зависимые переменные – это переменные, значения которых можно только измерять.
Переменные могут быть измерены в различных шкалах. Различие шкал определяется их информативностью. Рассматривают следующие типы шкал, представленные в порядке возрастания их информативности: номинальная, порядковая, интервальная, шкала отношений, абсолютная. Эти шкалы отличаются друг от друга также и количеством допустимых математических действий. Самая «бедная» шкала – номинальная, так как не определена ни одна арифметическая операция, самая «богатая» – абсолютная.
Измерение в номинальной (классификационной) шкале означает определение принадлежности объекта (наблюдения) к тому или иному классу. Например: пол, род войск, профессия, континент и т.д. В этой шкале можно лишь посчитать количество объектов в классах – частоту и относительную частоту.
Измерение в порядковой (ранговой) шкале, помимо определения класса принадлежности, позволяет упорядочить наблюдения, сравнив их между собой в каком-то отношении. Однако эта шкала не определяет дистанцию между классами, а только то, какое из двух наблюдений предпочтительнее. Поэтому порядковые экспериментальные данные, даже если они изображены цифрами, нельзя рассматривать как числа и выполнять над ними арифметические операции 5 . В этой шкале дополнительно к подсчету частоты объекта можно вычислить ранг объекта. Примеры переменных, измеренных в порядковой шкале: бальные оценки учащихся, призовые места на соревнованиях, воинские звания, место страны в списке по качеству жизни и т.д. Иногда номинальные и порядковые переменные называют категориальными, или группирующими, так как они позволяют произвести разделение объектов исследования на подгруппы.
При измерении в интервальной шкале упорядочивание наблюдений можно выполнить настолько точно, что известны расстояния между любыми двумя их них. Шкала интервалов единственна с точностью до линейных преобразований (y = ax + b). Это означает, что шкала имеет произвольную точку отсчета – условный нуль. Примеры переменных, измеренных в интервальной шкале: температура, время, высота местности над уровнем моря. Над переменными в данной шкале можно выполнять операцию определения расстояния между наблюдениями. Расстояния являются полноправными числами и над ними можно выполнять любые арифметические операции.
Шкала отношений похожа на интервальную шкалу, но она единственна с точностью до преобразования вида y = ax. Это означает, что шкала имеет фиксированную точку отсчета – абсолютный нуль, но произвольный масштаб измерения. Примеры переменных, измеренных в шкале отношений: длина, вес, сила тока, количество денег, расходы общества на здравоохранение, образование, армию, средняя продолжительность жизни и т.д. Измерения в этой шкале – полноправные числа и над ними можно выполнять любые арифметические действия.
Абсолютная шкала имеет и абсолютный нуль, и абсолютную единицу измерения (масштаб). Примером абсолютной шкалы является числовая прямая. Эта шкала безразмерна, поэтому измерения в ней могут быть использованы в качестве показателя степени или основания логарифма. Примеры измерений в абсолютной шкале: доля безработицы; доля безграмотных, индекс качества жизни и т.д.
Большинство статистических методов относятся к методам параметрической статистики, в основе которых лежит предположение, что случайный вектор переменных образует некоторое многомерное распределение, как правило, нормальное или преобразуется к нормальному распределению. Если это предположение не находит подтверждения, следует воспользоваться непараметрическими методами математической статистики.
Понятие временного ряда
Временные ряды – это наиболее интенсивно развивающееся, перспективное направление математической статистики. Под временным (динамическим) рядом подразумевается последовательность наблюдений некоторого признака Х (случайной величины) в последовательные равноотстоящие моменты t. Отдельные наблюдения называются уровнями ряда и обозначаются хt, t = 1, …, n. При исследовании временного ряда выделяются несколько составляющих:
xt=ut+yt+ct+et, t = 1, …, n,
где ut – тренд, плавно меняющаяся компонента, описывающая чистое влияние долговременных факторов (убыль населения, уменьшение доходов и т.д.); – сезонная компонента, отражающая повторяемость процессов в течение не очень длительного периода (дня, недели, месяца и т.д.); сt – циклическая компонента, отражающая повторяемость процессов в течение длительных периодов времени свыше одного года; t – случайная компонента, отражающая влияние не поддающихся учету и регистрации случайных факторов. Первые три компоненты представляют собой детерминированные составляющие. Случайная составляющая образована в результате суперпозиции большого числа внешних факторов, оказывающих каждый в отдельности незначительное влияние на изменение значений признака Х. Анализ и исследование временного ряда позволяют строить модели для прогнозирования значений признака Х на будущее время, если известна последовательность наблюдений в прошлом.
Методы механического сглаживания временных рядов
Метод простой скользящей средней
выбирается шаг сглаживания m, для упрощения m - нечетное;
уровни сглаженного ряда находятся по формуле:
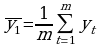
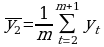
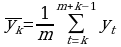
k =1, n-m+1, p=(m-1)/2
В итоге получается сглаженный динамический ряд:
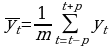
Метод взвешенной скользящей средней
Уровни, входящие в интервал сглаживания суммируются с разными весами. Полином берется со второй степени. Используется формула средней арифметической средней:
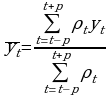
Для полиномов второго и третьего порядков при m=5 ρt{-3,12,17,12,-3},
m=7 ρt{5,-30,75,131,75,-30,5}
Метод экспоненциального сглаживания
вычисляется начальное значение S0 (либо, равный первому значению ряда, либо средней арифметической нескольких первых переменных);
сглаженное значение уровней St определяют по формуле
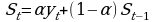 , где α – параметр сглаживания
, где α – параметр сглаживания 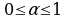 (
(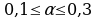 ) или
) или 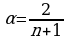 .
.
Методы выявления во временном ряду периодических колебаний
Метод «пиков» и «ям»
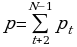 ,
,
N – число уровней ряда, где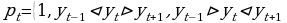 , 0 – в остальных случаях.
, 0 – в остальных случаях.
Далее проверяется нулевая гипотеза о случайном колебании ряда H0: колебания ряда случайны, H1: ряд имеет периодическую компоненту.
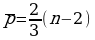
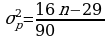
Критерием случайности с 5% уровнем значимости является выполнение неравенства:
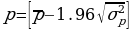
Если неравенство выполняется, то H0 принимается и наоборот.
Методы аналитического выравнивания
Для уравнения тренда в общем случае наиболее часто выбирают следующие функции:
Линейная: 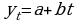 ;
;
Параболическая k-й степени (k=2,3…) 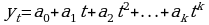 ;
;
Экспоненциальная: 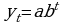 ;
;
Модифицированная экспоненциальная: 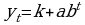 ;
;
Логистическая: 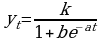 ;
;
Выбор обычно производится по сглаженному динамическому ряду. На практике используют как основной метод средних приростов. В зависимости от шага сглаживания значения средних приростов находят по формулам:
При m=3 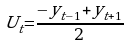 ;
;
При m=5 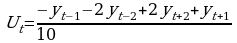 ;
;
При m=7 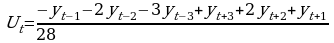 ;
;
Для выбора аппроксимирующей кривой используются следующие показатели:
| Показатель | Характер изменения показателя во времени | Вид кривой |
|
| Примерно одинаковый | Линейная: |
|
| Линейно изменяется | Параболическая 2-й степени |
|
| Примерно одинаковый | Экспоненциальная: |
|
| Линейно изменяется | Модифицированная экспоненциальная: |
|
| Линейно изменяется | Логистическая: |






Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!
Полезное для учителя

Реализация образовательных программ осуществляется с применением исключительно электронного обучения и ДОТ



