
Россия, Симферополь


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Была в сети 13.09.2025 13:18

Буркова Татьяна Юрьевна
Учитель информатики и математики
Местоположение
Специализация
7 класс. Представление текстов в памяти компьютера.
Категория:
Информатика
26.11.2018 22:55

Просмотр содержимого документа
«7 класс. Представление текстов в памяти компьютера.»
7 класс.
Информатика
Тема: Представление текстов в памяти компьютера. Кодировочные таблицы.
Цели урока:
познакомить учащихся со способами кодирования текстовой информации в компьютере;
научить вычислять информационный объем текста;
научить определять числовые коды символов, определять символы по их кодам;
воспитание аккуратности и умение вести записи в тетради, воспитание культуры поведения на уроке, умение слушать;
развитие познавательных интересов, умения конспектировать.
Планируемые результаты обучения:
Познавательные УУД:
умение осознано строить речевое высказывание в устной форме;
построение логической цепи рассуждений;
умение анализировать текст с целью выявления ошибок;
отвечать на простые вопросы учителя;
умение выбирать наиболее эффективные способы решения задач в зависимости от
конкретных условий.
Коммуникативные УУД:
умение оформлять свои мысли в устной форме;
умение слушать и понимать речь других;
умение совместно договариваться о правилах поведения и общения;
умение взаимодействовать в паре.
РегулятивныеУУД:
определение и формулирование целей на уроке с помощью учителя;
проговаривание последовательности действий на уроке;
планирование своих действий в соответствии с поставленной задачей;
контроль своей деятельности по ходу выполнения задания;
внесение необходимых коррективов в действие после его завершения на основе его
оценки и учёта характера сделанных ошибок;
Личностные УУД:
формирование интереса (мотивации) к учению;
осознание роли ученика;
умение проводить самооценку.
Основные понятия: кодировка, кодовая таблица, двоичный код, 8-миразрядные и 16-
тиразрядные кодировки, ASCII, КОИ8-Р, Windows, Unicode.
Межпредметные связи:
владение основными универсальными умениями информационного характера:
постановка и формулирование проблемы; поиск и выделение необходимой
информации, применение методов информационного поиска; структурирование и
визуализация информации; выбор наиболее эффективных способов решения задач в
зависимости от конкретных условий;
владение информационным моделированием как основным методом приобретения
знаний: умение преобразовывать объект из чувственной формы в знаково-
символическую модель; умение строить разнообразные информационные структуры
для описания объектов; умение «читать» таблицы, самостоятельно перекодировать
информацию из одной знаковой системы в другую;
Изучаемые вопросы:
Преимущества файлового хранения текстов.
Кодирование текстов.
Кодировочная таблица, международный стандарт ASCII.
Ход урока:
Организационный момент.
Постановка проблемы. Целеполагание. Мы с вами рассмотрели основные и дополнительные устройства компьютера, а также устройство ПК. А теперь мы будем знакомиться с применением компьютера. Компьютер может работать с разными видами информации: текстовой, графической, числовой и звуковой. Одним из самых массовых приложений ЭВМ является работа с текстами. Информация, представленная в виде текста, не является непрерывной. Текст состоит из символов – букв, цифр, знаков препинаний и т.д. А в каком виде информация хранится в памяти компьютера? – В двоичном коде. Каким образом символы преобразуются в двоичный код? – Каждому символу дается номер. А в каком порядке мы расположим символы? - Запишем в таблицу. Такие таблицы называются кодировочными, это будет темой нашего урока.
Тема нашего урока «Представление текстов в памяти компьютера. Кодировочные таблицы».
Знать: что такое кодировочные таблицы, способы кодирования.
Уметь: вычислять информационный объем текста, определять код символа, определять символ по его коду.
Объяснение нового материала.
Имея компьютер, можно создавать тексты, не тратя на это много времени и бумагу.
Иногда бывает так, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, невозможно прочитать - на экране монитора видна какая-то "абракадабра".
Ребята, как вы думаете, почему это происходит?
Пока у вас еще нет точного ответа. В конце урока попробуем еще раз ответить на этот вопрос.
Так как представлены тексты в памяти компьютера?
С точки зрения компьютера текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "%" и даже пробелы между словами.
Это могут быть математические или химические формулы, номера телефонов, числовые таблицы.
Множество символов, с помощью которых записывается текст, называется алфавитом. Число символов в алфавите – это его мощность.
Формула определения количества информации: N = 2i,
где N – мощность алфавита (количество символов),
i – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 28, то вес 1 символа – 8 бит.
Единице измерения 8 бит присвоили название 1 байт: 1 байт = 8 бит.
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Пример 1. Сколько бит памяти компьютера занимает слово МИКРОПРОЦЕССОР?
Решение. Слово состоит из 14 букв. Каждая буква является символом компьютерного алфавита и поэтому занимает 1 байт памяти. Слово займет 14 байт = 112 бит памяти, т.к. 1 байт = 8 бит.
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам символы. В оперативную память они попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный код.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки. Международным стандартом для ПК стала таблица ASCII (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части.
Символы с номерами от 0 до 31 принято называть управляющими. Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п.
Символ 32 - пробел, т.е. пустая позиция в тексте. Все остальные отражаются определенными знаками. Стандартная часть таблицы (английский) символы с номерами от 32 до 127. Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы.
Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер.
Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита. Для букв русского алфавита также соблюдается принцип последовательного кодирования.
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Попробуем с помощью таблицы ASCII представить, как будут выглядеть слова в памяти компьютера.
| Слова | Память |
| file | 01100110 01101001 01101100 01100101 |
| disk | 01100100 01101001 01110011 01101011 |
А теперь давайте еще раз попробуем ответить на вопрос, который был задан в начале урока:
Почему иногда текст, состоящий из букв русского алфавита, полученный с другого компьютера, мы видим на своем компьютере в виде "абракадабры"?
Ожидаемый ответ. На компьютерах применяется разная кодировка символов русского языка.
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Первичное закрепление.
Пример 1. Сколько бит памяти компьютера занимает выражение жесткий диск?
Прежде, чем приступить к решению примера, вспомним,
какой объем памяти занимает один символ компьютерного текста.
Ожидаемый ответ. 1 байт
Решение. Слово состоит из 14 букв. Каждая буква является символом компьютерного алфавита и поэтому занимает 1 байт памяти. Слово займет 14 байт = 112 бит памяти, т.к. 1 байт = 8 бит.
В чем заключается принципа последовательного кодирования алфавита?
Ожидаемый ответ. В таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений.
*Примеры из презентации.
5. Практическая работа.
Файл «ПР Кодирование текста». Сохранить в своей папке и редактировать. В практической работе 4 задачи.
Подведение итогов. Оценивание. Предлагается дать оценку работе своей и товарищей.
Домашнее задание: § 13; вопросы, №6 письменно.
Практическое задание по теме «Кодирование текстовой информации»
Дата: ____________
Работу выполнил: _______________
Сколько бит памяти компьютера занимает слово ЦВЕТЫ в кодировке КОИ8-Р?
Дано:
k = …. букв
i = 8 бит
Решение:
ЦВЕТЫ - ….. букв
Iслова = k*i = ….*…. = …. бит.
Ответ: Слово ЦВЕТЫ занимает …. бит информации.
Найти:
Iслова = ?
Закодируйте слово file с помощью кодировочной таблицы ASCII. Откройте диалоговое окно Вставка – Символ – Другие символы.

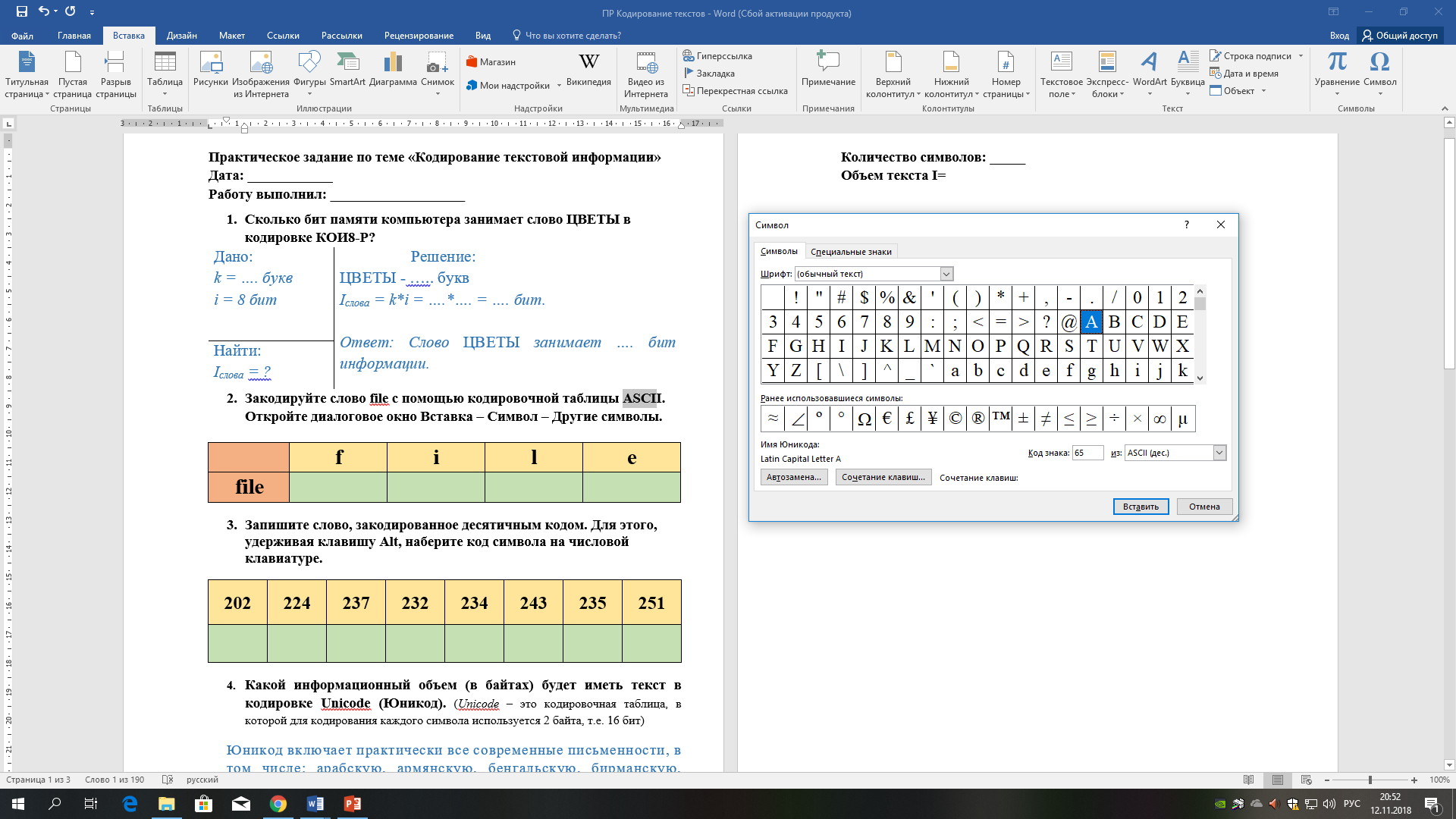

|
| f | i | l | e |
| file |
|
|
|
|
Запишите слово, закодированное десятичным кодом. Для этого, удерживая клавишу Alt, наберите код символа на числовой клавиатуре.
| 138 | 128 | 141 | 136 | 138 | 147 | 139 | 155 |
|
|
|
|
|
|
|
|
|
Какой информационный объем (в байтах) будет иметь текст в кодировке Unicode (Юникод). (Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит).
Для подсчета количества символов выделите текст и откройте окно Статистика, выполнив щелчок по надписи: «Число слов» в левом нижнем углу окна.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
В эту таблицу добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
Количество символов: _____
Объем текста I=
7








Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!

