
Россия, Воронеж


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Была в сети 02.06.2026 15:03

Сенькевич Елена Владимировна
преподаватель
48 лет
Местоположение
Специализация
Лекция Кодирование текстовой информации
Категория:
Информатика
17.09.2022 11:16

Просмотр содержимого документа
«Лекция Кодирование текстовой информации»
ТЕМА «Кодирование текстовой информации»
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и т.п. и даже (обратите особое внимание!) пробелы между словами. Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение.
Вся информация в компьютере хранится в двоичном коде. Поэтому надо научиться преобразовывать символы в двоичный код.
Множество символов, с помощью которых записывается текст, называется алфавитом.
Число символов в алфавите – это его мощность.
Формула определения количества информации:
N = 2b,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 28, то вес 1 символа – 8 бит.
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
В оперативную память символы попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части (смотреть приложение 2).
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII| Порядковый номер | Код | Символ |
| 0 - 31 | 00000000 - 00011111 | Символы с номерами от 0 до 31 принято называть управляющими. Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п. |
| 32 - 127 | 00100000 - 01111111 | Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. Символ 32 - пробел, т.е. пустая позиция в тексте. Все остальные отражаются определенными знаками. |
| 128 - 255 | 10000000 - 11111111 | Альтернативная часть таблицы (русская). Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер. Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита. |
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита так же в основном соблюдается принцип последовательного кодирования.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
| Слово 1 | Память ПК |
| Слово 2 | Память ПК | ||
| file | f | 01100110 | disk | d | 01100100 | |
| i | 01101001 | i | 01101001 | |||
| l | 01101100 | s | 01110011 | |||
| e | 01100101 | k | 01101011 | |||
Каждый символ текста кодируется восьмиразрядным двоичным кодом. Для представления текстов в компьютере используется алфавит мощностью 256 символов.
В таблице кодировки каждому символу алфавита поставлен в соответствие порядковый номер и восьмиразрядный двоичный код.
Все символы кодируются одинаковым числом бит (алфавитный подход)
Международным стандартом является код ASCII - американский стандартный код для информационного обмена.
Чаще всего используют кодировки, в которых на символ отводится 8 бит (8-битные ASCII) или 16 бит (16-битные Unicode)
После знака препинания внутри (не в конце!) текста ставится пробел
При измерении количества информации принимается, что в одном байте 8 бит, а в одном килобайте (1 Кбайт) – 1024 байта, в мегабайте (1 Мбайт) – 1024 Кбайта
Чтобы найти информационный объем текста I, нужно умножить количество символов N на число бит на символ K :
I=N*K
Примеры решения задач
Пример 1 Закодируйте кодом ASCII слово MOSCOW.
Решение:
Составим таблицу и поместим туда слово MOSCOW. Используя таблицу ASCII кодов, закодируем все буквы слова:
| M | O | S | C | O | W |
| 01001101 | 01001111 | 01010011 | 01000011 | 01001111 | 01110111 |
ОТВЕТ:
100110110011111010011100001110011111110111
Пример 2
Задача 1. Информационный объём сообщения составляет 8,5 Кбайт (I). Данное сообщение содержит 8704 символа (N). Какое минимально возможное количество символов содержится в использованном алфавите?
Решение задачи 1.
Информационный объём сообщения 8,5 Кбайт = 8,5 * 1024 = 8704 байта
I / N = K (число бит на символ)
8704 байта / 8704 символа = Одному символу сообщения соответствует 1 байт = 8 бит
С помощью 8 бит (1 байта) можно закодировать 28 = 256 символов, это меньше количества символов, содержащихся в сообщении.
Ответ:
В использованном алфавите содержится 256 символов, что соответствует полному алфавиту ASCII.
Пример 3
Задача 2.
Автоматическое устройство осуществило перекодировку информационного сообщения, первоначально записанного в 7-битном коде ASCII, в 16-битную кодировку Unicode. При этом информационное сообщение увеличилось на 108 бит.
Какова длина сообщения в символах?
1) 12
2) 27
3) 6
4) 62
Решение задачи 2.
Изменение кодировки с 7 бит на 16 бит, равно 16 - 7 = 9 бит. Следовательно информационный объем каждого символа сообщения увеличился на 9 бит. По условиям задачи информационный объем сообщения после кодировки составил 108 бит, следовательно количество символов в сообщении = 108/9 = 12.
Ответ: 1) 12 символов.
Пример 4
Задача 3.
В одной из кодировок Unicode каждый символ кодируется 16 битами.
Определите размер следующего предложения в данной кодировке:
«Тише едешь – дальше будешь!»
216 бит
27 байт
54 байта
46 байт
Решение задачи 3:
Каждый символ кодируется 16 битами. Значит общее количество бит во всем предложении равно количеству символов умноженному на 16. Аккуратно подсчитаем количество символов в предложении, не забывая при этом пробелы между словами. Получаем 27 символов, умножаем 27 на 16, получаем 432 бита. Такого ответа нет среди предлагаемых вариантов. Переведем полученную величину в байты. То есть поделим 432 на 8 (или изначально можно было умножить 27 на 2, а не на 8). Получаем 54 байта.
Ответ: 3) 54 байта.
ЗАКРЕПЛЕНИЕ МАТЕРИАЛА.
Задание 1. Расшифруйте сообщение, используя таблицу ASCII.
| 1001001 |
|
| 1101110 |
|
| 1100110 |
|
| 1101111 |
|
| 1110010 |
|
| 1101101 |
|
| 1100001 |
|
| 1110100 |
|
| 1101001 |
|
| 1101111 |
|
| 1101110 |
|
Задание 2.
Задача. Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения:
Один пуд – около 16,4 килограмм.
ПРИЛОЖЕНИЕ 1
Аналогичные (Базовой таблице кодировки ASCII) системы кодирования текстовых данных были разработаны и в других странах.
Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших.
Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 1.2). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
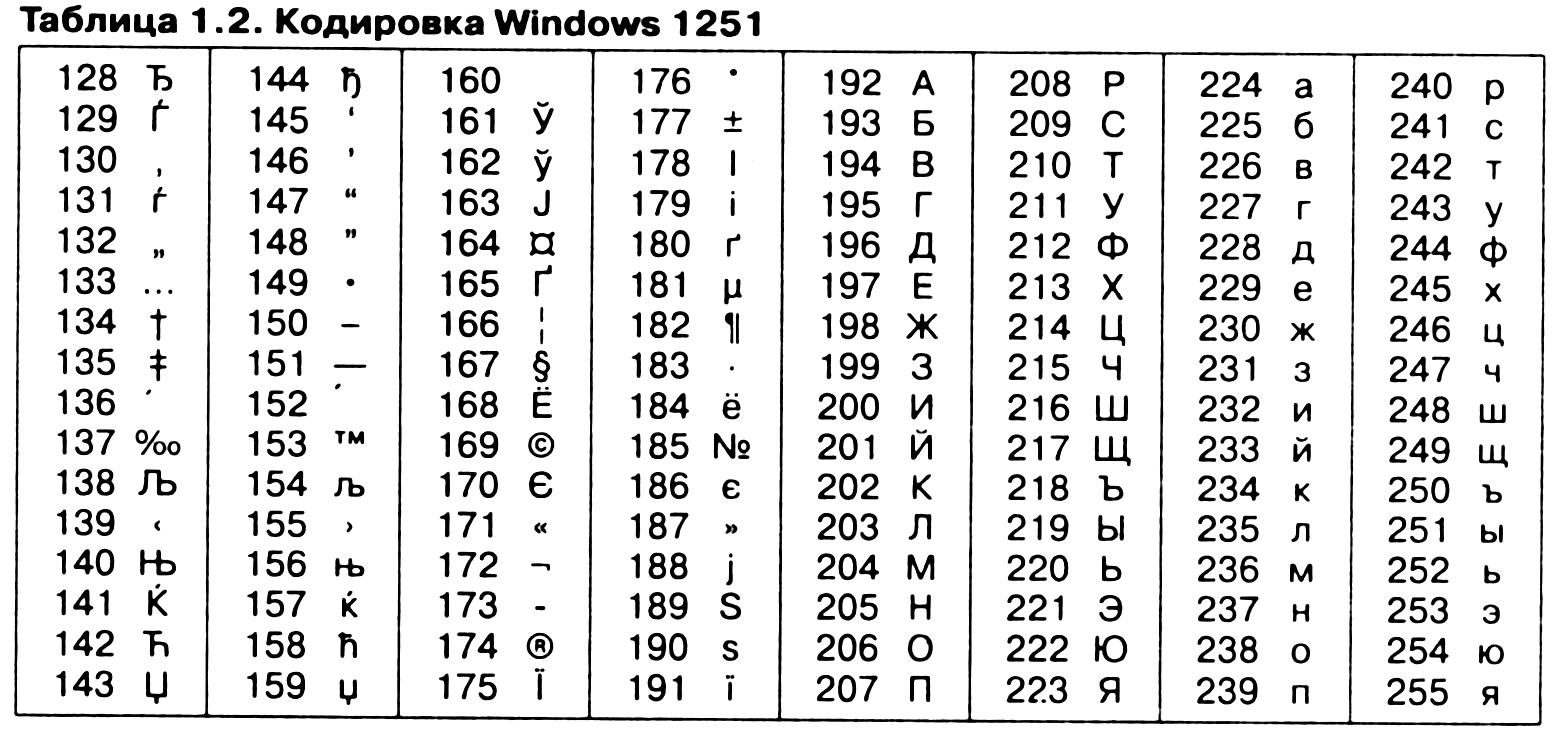
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) — ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (таблица 1.3). Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.

Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки /50 (International Standard Organization — Международный институт стандартизации). На практике данная кодировка используется редко (таблица 1.4).

На компьютерах, работающих в операционных системах MS-DOS, могут действовать еще две кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая из них считалась устаревшей даже в первые годы появления персональной вычислительной техники, но вторая используется и по сей день (см. таблицу 1.5).

В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных — это одна из распространенных задач информатики.
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.

8








Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!

