Республика Крым, Симферополь


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Был в сети 13.02.2025 10:35

Нестеров Дмитрий Сергеевич
Преподаватель
Местоположение
Специализация
План-конспект лекции "Модели, используемые при разработке и создании баз данных."
Категория:
Информатика
13.02.2025 09:26

Просмотр содержимого документа
«План-конспект лекции "Модели, используемые при разработке и создании баз данных."»
Тема Лекции № 3_4 Модели, используемые при разработке и создании баз данных.
1.2. Автоматизированная информационная система
.Под автоматизированной информационной системой (АИС) будем понимать
совокупность программно-аппаратных средств, предназначенных для
автоматизации деятельности, связанной с хранением, передачей и обработкой информации.
АИС, основанная на базе данных, служит для сбора, накопления, хранения
информации, а также её эффективного использования для различных целей.
Информация представляется в виде данных, хранимых в памяти ЭВМ. При
проектировании АИС, с одной стороны, решается вопрос о том, какие сведения и для каких целей будут содержаться в системе, с другой – как соответствующие данные будут организованы в памяти ЭВМ и как они будут
обрабатываться при эксплуатации АИС.
По сферам применения и правилам организации различают два основных класса АИС, основанных на базе данных: информационно-поисковые (ИПС)
и системы обработки данных(СОД). ИПС ориентированы, как правило, на
извлечение подмножества хранимых данных, удовлетворяющих некоторому
поисковому критерию. Пользователя ИПС интересует, в основном, сами
извлекаемые из базы данных сведения, а не результаты их обработки. Примером ИПС является любая справочная служба: к ней обращаются с запросом и получают в результате те данные, которые удовлетворяют этому запросу. Обращения пользователя к СОД чаще всего приводят к обновлению данных.
Вывод данных может вовсе отсутствовать или представлять собой результат
программной обработки хранимых сведений. Пример СОД – банковские
системы, осуществляющие открытие/закрытие счетов, пересчёт вкладов в
зависимости от процентов, приём/снятие сумм и т.п.
В зависимости от характера информационных ресурсов, с которыми имеют дело АИС, их подразделяют на документальные и фактографические. На практике используются также системы комбинированного типа.
Фактографические АИС хранят сведения об объектах предметной области, их свойствах и взаимосвязях. Сведения о каждом объекте могут поступать в
систему из множества различных источников. Кроме поиска и модификации
данных, фактографические системы поддерживают статистические функции
(нахождение суммы, минимума, максимума и т.п.). Фактографические АИС
обычно принадлежат к классу систем обработки данных.
В документальной системе объект хранения – документ, который содержит
информацию, относящуюся к определённой предметной области. Это могут
быть графические изображения (например, географические карты); информация на естественном языке (монографии, тексты законодательных актов, научные отчёты и т.п.); звуковая информация (например, мелодии для системы, хранящей фонотеку) и т.д. Для обработки данных не важно, какие сведения хранятся в документах. Обычно (но не всегда) документальные АИС реализуются в виде информационно-поисковых систем (ИПС).
Основные компоненты документальной ИПС:
программные средства;
поисковый массив документов;
средства поддержки информационного языка системы.
Программные средства ИПС служат для организации управления данными
(ввода, хранения, защиты, поиска и выдачи). Поисковый массив документов в ИПС обычно называется базой данных. Он представляет собой набор ссы-лок на документы (или их описаний), хранящий основную информацию о документах и организованный так, чтобы обеспечить быстрый поиск документов. Описание документа зависит от предметной области и состоит из значений атрибутов, характеризующих содержание документа. Например, для БД географических карт это могут быть координаты и масштаб, а для БД законодательных актов – тип документа (закон, постановление и др.), дата принятия, область действия и т.п.
Информационный язык ИПС предназначен для того, чтобы пользователь мог запросить данные у системы. Системными средствами пользовательский запрос преобразуется в формальный запрос, понятный системе. Информационный язык ИПС может быть основан на подмножестве естественного языка, которое относится к обслуживаемой ПО. Но чаще поиск документа осуществляется с помощью шаблонов – экранных форм, включающих поля описания документа.
В эти поля вносятся конкретные значения, которые и определяют условия
поиска документов. Мы будем основное внимание уделять фактографическим АИС, имея в виду, что ИПС и документальные АИС создаются с помощью тех же программных средств и на тех же принципах, что и СОД, а специфические моменты обработки данных реализуются через приложения (программы, внешние по отношению к ядру СОД).
Разработка любой АИС начинается с определения предметной области.
1.3. Предметная область информационной системы
Предметная область (ПО) информационной системы рассматривается как
совокупность реальных процессов и объектов (сущностей), представляющих
интерес для её пользователей [7]. Каждая из сущностей ПО обладает
определённым набором свойств (атрибутов), среди которых можно выделить
существенные и малозначительные. Признание какого-либо свойства
существенным носит относительный характер.
Например, атрибут Должность для сотрудника является существенным, а для читателя библиотеки – малозначительным.
Для упрощения процедуры формализации ПО в большинстве случаев
прибегают к определению типов сущностей. Тип позволяет выделить из всего множества сущностей ПО группу сущностей, однородных по структуре и поведению (относительно рамок рассматриваемой ПО). Например, для ПО
"Институт" в качестве типов сущностей могут рассматриваться студенты,
преподаватели, дисциплины и т.п. Данные предметной области представляются экземплярами сущностей (студент Иванов, преподаватель Сидоров, дисциплина "Базы данных"). Экземпляры сущностей одного типа обладают одинаковыми наборами атрибутов, но должны отличаться значением хотя бы одного атрибута для того, чтобы быть узнаваемыми (например, студенты могут иметь
одинаковые ФИО, но должны иметь разные номера зачётных книжек).
Между сущностями ПО могут существовать связи, имеющие различный
содержательный смысл (семантику). Например, студент учится в группе,
врач лечит пациента, клиент имеет вклад в банке. Связи могут
быть факультативными или обязательными. Если вновь порождённая
сущность одного из типов оказывается по необходимости связанной с
сущностью другого типа, то между этими типами сущностей есть обязательная связь. Иначе связь является факультативной.
Выделяют также показатель кардинальности связи: "один к
одному" (1:1), "один ко многим" (1:n) и "многие ко многим" (m:n) (рис. 1.4).
Степень связи – это количество сущностей, которые входят в связь.
Различают тип связи и экземпляр связи.
Совокупность типов сущностей и типов связей между ними характеризует
структуру предметной области. Собственно данные представлены экземплярами сущностей и связей между ними. Данные экземпляров сущностей и связей хранятся в базе данных информационной системы, а описание типов сущностей и связей является метаданными.
Множества экземпляров сущностей, значения атрибутов сущностей и
экземпляры связей между ними могут изменяться во времени. Поэтому каждому моменту времени можно сопоставить некоторое состояние предметной области. Состояния ПО должны подчиняться совокупности правил, которые характеризуют семантику предметной области. В базе данных эти правила могут быть заданы с помощью так называемых ограничений целостности, которые накладываются на атрибуты сущностей, типы сущностей, типы связей
и/или их экземпляры. Фактически, ограничения целостности – это правила,
которым должны удовлетворять значения данных в БД. Например, для
библиотеки можно привести такие ограничения целостности: количество
экземпляров книги не может быть отрицательным; номер паспорта читателя
должен быть уникальным; каждая книга относится к определённому разделу
рубрикатора ББК – библиотечно-библиографической классификации и т.д.
Для того чтобы обеспечить соответствие базы данных текущему состоянию
предметной области, база данных динамически обновляется (периодически или
в режиме реального времени). Это обновление называется актуализацией
данных.
Актуализация может проводиться:
вручную, если изменения в данные вносит пользователь (например,
запись сведений о выдаче абоненту книги в библиотеке);
автоматизировано, если изменения инициируются пользователем, но выполняются программно (например, обновление списка должников в
библиотеке – читателей, которые просрочили дату возврата книг);
автоматически, если данные поступают в электронном виде и обрабатываются программой без участия человека (это касается, например,
автоматизированных систем управления производством).
Правильность обновлений может контролироваться программно, но правильнее
контролировать их автоматически с помощью ограничений целостности БД.
База данных является информационной моделью внешнего мира, некоторой
предметной области. Во внешнем мире сущности ПО взаимосвязаны, поэтому в
БД эти связи должны быть отражены. Если связи между данными в БД
отсутствуют, то имеет смысл говорить о нескольких независимых БД и хранить
их раздельно.
1.4. Назначение и основные компоненты системы баз
данных
Система БД включает два основных компонента: собственно базу данных и
систему управления базами данных – СУБД. Большинство СОД
включают также программы обработки данных (прикладное программное
обеспечение, ППО), которые обращаются к дан-ным через СУБД.
СУБД обеспечивает выполнение двух групп функций:
предоставление доступа к базе данных прикладному программному
обеспечению (или квалифицированным пользователям);
управление хранением и обработкой данных в БД.
Таким образом, обращение к базе данных возможно только через СУБД.
БД предназначена для хранения данных информационной системы.
Пользователи обращаются к базе данных обычно не напрямую через средства
СУБД, а с помощью внешнего интерфейса – приложения, входящего в состав
АИС. Если пользователей можно разделить на группы по характеру решаемых
задач, то приложений может быть несколько (по количеству задач или групп
пользователей). Например, для библиотеки можно выделить три группы
пользователей: читатели, которым нужно осуществлять поиск книг по
различным признакам; сотрудники, выдающие и принимающие у читателей
книги (библиотекари) и сотрудники отдела комплектации, осуществляющие
приём новых книг и списание старых.
1.5. Уровни представления данных
Современная технология баз данных основана на концепции многоуровневой
архитектуры СУБД. Эти идеи впервые были сформулированы в отчёте рабочей группы по базам данных Комитета по планированию стандартов Американского национального института стандартов (ANSI/X3/SPARC). Этот отчёт был опубликован в 1975 г. В нём была предложена обобщенная трёхуровневая модель архитектуры СУБД, включающая концептуальный, внешний и внутренний уровни
Концептуальный уровень архитектуры ANSI/SPARC служит для поддержки
единого взгляда на базу данных, общего для всех её приложений и
независимого от них и от среды хранения [6]. Концептуальный уровень
представляет собой формализованную информационно-логическую модель ПО. Описание этого представления называется концептуальной схемой или схемой БД.
Внутренний уровень архитектуры поддерживает представление данных в
среде хранения и пути доступа к ним [6]. На этом архитектурном уровне БД
представлена в полностью "материализованном" виде, тогда как на других
уровнях идёт работа на уровне отдельных экземпляров или множества
экземпляров данных. Описание БД на внутреннем уровне
называетсявнутренней схемой или схемой хранения.
Внешний уровень архитектуры БД предназначен для групп пользователей.
Описание представления данных для группы пользователей называется
внешней схемой. Наличие внешнего уровня позволяет поддерживать разное
представление одних и тех же данных для различных групп пользователей или задач.
Каждый из этих уровней может считаться управляемым, если он об-ладает
внешним интерфейсом, который обеспечивает возможности определения
данных. В этом случае становится возможными формирование и системная
поддержка независимого взгляда на БД для какой-либо группы персонала или пользователей, взаимодействующих с БД через интерфейс данного уровня.
В архитектурной модели ANSI/SPARC предполагается наличие в СУБД
механизмов, обеспечивающих междууровневое отображение данных "внешний – концептуальный" и "концептуальный – внутренний". Функциональные возможности этих механизмов определяют степень независимости данных на всех уровнях. На переходе "внешний – концептуальный" обеспечивается логическая независимость данных, на переходе "концептуальный – внутренний" – физическая независимость. Под логической независимостью подразумевается возможность вносить изменения в концептуальный уровень, не меняя представление БД для пользователей, или изменять представление данных для пользователей без изменения концептуальной схемы. Физическая независимость данных подразумевает возможность вносить изменения в схему хранения, не меняя концептуальную схему БД.
Основной характеристикой баз данных является совместное использование
данных многими пользователями АИС. Должно существовать какое-то общее понимание информации, представленной данными. Общее понимание должно относиться к чему-либо внешнему по отношению к пользователям, и оно должно быть зафиксировано. Для этого необходима некоторая предварительно определённая грамматика, которую принято называть моделью данных.
"Границы моего языка означают
границы моего мира".
Людвиг Витгенштейн, англоавстрийский философ и логик
2. ОСНОВНЫЕ МОДЕЛИ ДАННЫХ
Модель данных является инструментом моделирования произвольной
предметной области.
2.1. Понятие модели данных
Модель данных – это совокупность правил порождения структур данных в базе данных, операций над ними, а также ограничений целостности, определяющих допустимые связи и значения данных, последовательность их изменения [6].
Итак, модель данных состоит из трёх частей:
1. Набор типов структур данных.
Здесь можно провести аналогию с языками программирования, в которых
тоже есть предопределённые типы структур данных, такие как скалярные
данные, вектора, массивы, структуры (например, тип struct в языке Си) и
т.д.
2. Набор операторов или правил вывода, которые могут быть применены к
любым правильным примерам типов данных, перечисленных в (1), чтобы
находить, выводить или преобразовывать информацию, содержащуюся в
любых частях этих структур в любых комбинациях.
Такими операциями являются: создание и модификация структур данных,
внесение новых данных, удаление и модификация существующих
данных, поиск данных по различным условиям.
3. Набор общих правил целостности, которые прямо или косвенно
определяют множество непротиворечивых состояний базы данных и/или
множество изменений её состояния.
Правила целостности определяются типом данных и предметной областью.
Например, значение атрибута Счётчик является целым числом, т.е. может
состоять только из цифр. А ограничения предметной области таковы, что это
число не может быть меньше нуля.
Теперь рассмотрим подробнее наборы, составляющие модель данных.
2.1.1. Типы структур данных
Структуризация данных базируется на использовании концепций "агрегации" и "обобщения". Один из первых вариантов структуризации данных был
предложен Ассоциацией по языкам обработки данных (Conference on Data
Systems Languages, CODASYL)
Элемент данных – наименьшая поименованная единица данных, к которой
СУБД может обращаться непосредственно и с помощью которой выполняется построение всех остальных структур. Для каждого элемента данных должен быть определён его тип.
Агрегат данных – поименованная совокупность элементов данных внутри
записи, которую можно рассматривать как единое целое. Агрегат может быть
простым (включающим только элементы данных) и составным
(включающим наряду с элементами данных и другие агрегаты).
Запись – поименованная совокупность элементов данных или эле-ментов
данных и агрегатов. Запись – это агрегат, не входящий в состав никакого
другого агрегата; она может иметь сложную иерархическую структуру,
поскольку допускается многократное применение агрегации. Различают тип
записи (её структуру) и экземпляр записи, т.е. запись с конкретными
значениями элементов данных. Одна запись описывает свойства одной
сущности ПО (экземпляра). Иногда термин "запись" за-меняют термином
"группа".
Среди элементов данных (полей записи) выделяются одно или несколько
ключевых полей. Значения ключевых полей позволяют классифицировать
сущность, к которой относится конкретная запись. Ключи с уникальными
значениями называются потенциальными. Каждый ключ может представлять
собой агрегат данных. Один из ключей назначается первичным, остальные
являются вторичными. Первичный ключ идентифицирует экземпляр записи,
его значение должно быть уникальным и обязательным для записей одного
типа.
Набор (или групповое отношение) – поименованная совокупность записей,
образующих двухуровневую иерархическую структуру. Каждый тип набора
представляет собой связь между двумя или несколькими типами записей. Для
каждого типа набора один тип записи объявляется владельцем набора,
остальные типы записи объявляются членами набора. Каждый экземпляр набора должен содержать только один экземпляр записи типа владельца и столько экземпляров записей типа членов набора, сколько их связано с владельцем. Для группового отношения также различают тип и экземпляр.
Групповые отношения удобно изображать с помощью диаграммы Бахмана,
которая названа так по имени одного из разработчиков сетевой модели данных.
Диаграмма Бахмана – это ориентированный граф, вершины которого
соответствуют группам (типам записей), а дуги – групповым отношениям
База данных – поименованная совокупность экземпляров групп и групповых
отношений. Это самый высокий уровень структуризации данных.
Примечание: структуризация данных по версии CODASYL используется в
сетевой и иерархической моделях данных. В реляционной модели принята
другая структуризация данных, основанная на теории множеств.
2.1.2. Операции над данными
Модель данных определяет множество действий, которые допустимо
производить над некоторой реализацией БД для её перевода из одного
состояния в другое. Это множество соотносят сязыком манипулирования
данными (Data Manipulation Language, DML).
Любая операция над данными включает в себя селекцию данных (select), то
есть выделение из всей совокупности именно тех данных, над которыми должна быть выполнена требуемая операция, и действие над выбранными данными, которое определяет характер операции. Условие селекции – это некоторый критерий отбора данных, в котором могут быть использованы логическая позиция элемента данных, его значение и связи между данными.
По типу производимых действий различают следующие операции:
идентификация данных и нахождение их позиции в БД;
выборка (чтение) данных из БД;
включение (запись) данных в БД;
удаление данных из БД;
модификация (изменение) данных БД.
Обработка данных в БД осуществляется с помощью процедур базы данных –
транзакций.Транзакцией называют упорядоченное множество операций,
переводящих БД из одного согласованного состояния в другое. Транзакция либо выполняется полностью, т.е. выполняются все входящие в неё операции, либо не выполняется совсем, если в процессе её выполнения возникает ошибка.
2.1.3. Ограничения целостности
Ограничения целостности – это правила, которым должны удовлетворять
значения элементов данных. Ограничения целостности делятся
на явные и неявные.
Неявные ограничения определяются самой структурой данных. Например, тот факт, что запись типа СОТРУДНИК имеет поле Дата рождения, служит, по существу, ограничением целостности, означающим, что каждый сотрудник организации имеет дату рождения, причём только одну.
Явные ограничения включаются в структуру базы данных с помощью средств языка контроля данных (DCL, Data Control Language). В качестве явных ограничений чаще всего выступают условия, накладываемые на значения данных. За выполнением ограничений целостности следит СУБД в процессе своего
функционирования. Она проверяет ограничения целостности каждый раз, когда они могут быть нарушены (например, при добавлении данных, при удалении данных и т.п.), и гарантирует их соблюдение. Если какая-либо команда нарушает ограничение целостности, она не будет выполнена и система выдаст соответствующее сообщение об ошибке. Например, если задать в качестве ограничения правило «Остаток денежных средств на счёте не может быть отрицательным», то при попытке снять со счёта денег больше, чем там есть, система выдаст сообщение об ошибке и не позволит выполнить эту операцию.
Таким образом, ограничения целостности обеспечивают логическую
непротиворечивость данных при переводе БД из одного состояния в другое.
В настоящее время разработано много различных моделей данных. Основные – это сетевая, иерархическая и реляционная модели.
Иерархическая модель данных – модель с отношением подчиненности между данными.
Определение. Отношение объектов иерархической модели определяется следующими правилам:
А подчинено Б Б не подчинено А;
А подчинено Б (А подчинено В) (Б тождественно В),
где А, Б, В – объекты. Другими словами, иерархическая модель реализуется древовидной структурой.
Ясно, что иерархическая модель имеет дело с древовидными структурами, в которых объекты модели представлены узлами дерева.
Заметим, что данное определение не позволяет определить пустую модель, модель, состоящую из одного лишь корня. Кроме того, здесь допускается несвязная модель.
Иерархическая модель обладает следующими свойствами.
Существует корень.
Узел содержит атрибуты.
Исходный и зависимый узлы находятся в отношении «непосредственный предок и потомок». Узлы добавляются горизонтально и вертикально.
Потомок соединен единственной связью с предком.
Предок может иметь несколько потомков.
Доступ к данным производится через предка.
Может существовать множество экземпляров узла.
При удалении узла удаляется все его поддерево.
Пример
(А) (Б)

В модели (А) возникает избыточность, если хирург оперирует более одного пациента. Кроме того, возникают нежелательные явления, возникающие при работе с базой данных, которые называют аномалией.
Аномалия включения: В БД (А) невозможно включить не оперировавшего хирурга.
Аномалия удаления: так как при удалении узла исключаются и все его подузлы, то при удалении хирурга из (Б) исчезают все его пациенты.
На втором рисунке демонстрируется своеобразный выход из положения: организуются две иерархические базы со ссылками из нижних уровней одной к верхнему уровню другой. Аномалий в этом случае нет.
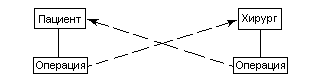
Конец примера
Достоинства
Простота в понимании и использовании.
Обеспечение определенного уровня независимости по сравнению с файловыми системами.
Простота обслуживания и оценки характеристик, так как благодаря дисциплине удаления нет нужды заботиться о висячих ссылках.
Высокая скорость доступа.
Недостатки
Основной недостаток – невозможность реализации отношения «многие к многим» в рамках одной базы данных. Реализация такого отношения на основе двух БД затрудняет управление.
Первая СУБД, построенная по иерархической модели – IMS компании IBM (1969 г.). Она до сих пор эксплуатируется на разных платформах. Кроме того, примером иерархической СУБД может служить ДИАМС, входящий в программное обеспечение ЭВМ типа СМ-4 (зарубежный аналог – MAMS фирмы DEC). Есть вариант этой СУБД и для персональных ЭВМ.
Сетевая модельСетевая модель основана на рекомендациях рабочей группы по базам данных КОДАСИЛ (CODASYL), которые стали фактически первым стандартом в области систем баз данных (1969-1978 гг.). В дальнейшем изложении используются терминология и ограничения, введенные этим комитетом.
Согласно рекомендациям, база данных делится на области, те – на записи, состоящие из полей. С другой стороны, база состоит из наборов, а те – из записей:
Пример
О
Пациент
Операция
Хирург

 бласть “Пациент” Область “Хирург” Связь «пациент-операция» означает «пациент перенес операцию», «хирург-операция» – «хирург выполнил операцию».
бласть “Пациент” Область “Хирург” Связь «пациент-операция» означает «пациент перенес операцию», «хирург-операция» – «хирург выполнил операцию». Конец примера
Определения
Запись – иерархия, образованная из простейших (атомарных) элементов данных, их групп и повторяющихся групп.
Множество допустимых экземпляров записи называется типом записи.
Тип набора – множество экземпляров набора. К набору относятся записи – члены набора и владелец набора. Записи-владельцы (члены) могут быть одновременно владельцами (членами) других наборов.
Первое определение совпадает с определением записи в языке КОБОЛ. Третье определение задает отношение «владелец-член».
Доступ к члену набора производится только через владельца. Тип набора имеет имя (уникальность владельца). Универсальный владелец в сетевой модели – это СУБД. Через нее выполняется доступ к самым «верхним» владельцам. Допускается и набор без владельца – сингулярный набор. В этом случае доступ к информации производит система, играя роль универсального владельца.
Ограничения КОДАСИЛ
Тип набора определяет отношение 1:М между типом записи-владельца и типом записи-члена.
Экземпляр типа записи-члена может участвовать только в одном экземпляре типа набора.
В сетевой модели отношение записей представляет собой граф, не имеющий циклов. Иерархическая модель может быть представлена как частный случай сетевой.
Пример
Отношение «пациент-хирург» – это отношение M:N, и согласно ограничению КОДАСИЛ, его впрямую реализовать нельзя. Однако проблема решатся просто, если пациент и хирург будут владельцами, а операция – членом набора:
Пациент
Хирург
Операция
Лечение



Такая связь часто называется Y-структурой. Кроме нее, встречаются другие связи:
иерархическая многочленная
Пациент
Пациент
Операция
Лечение


Операция
Заболевание

Конец примера
Наборы в сетевой базе данных могут иметь атрибуты. Атрибут «обязательный-необязательный» определяет поведение СУБД при удалении владельца экземпляра набора. В первом случае члены набора удаляются при удалении владельца, во втором случае – нет. Атрибут «автоматический-ручной» определяет способ включения в набор. В первом случае члены набора включаются в нужный экземпляр набора автоматически, во втором случае в нужный набор запись включается по команде из прикладной программы.
В сетевой базе данных существует понятие текущего состояния. Более того, это важная концепция языка манипуляции данными (ЯМД) КОДАСИЛ. В сведения о текущем состоянии входит структура базы, структуры наборов, связи и т.п. Наличие этих данных позволяет эффективно осуществлять доступ к данным, контролировать их целостность. Недостаток такого централизованного представления – трудности с изменением структуры данных.
Достоинства
Реализуется отношение "многие к многим".
Высокая производительность.
Недостатки
Основной недостаток сетевой модели – трудность реорганизации базы данных, то есть изменения ее структуры. Обычно реорганизация требует выгрузки данных с последующей их загрузкой в БД с новой структурой. При этом важно не только не потерять данные, но и корректно определить ссылки, в противном случае часть информации будет недоступной. Сама процедура реорганизации требует определенной квалификации администратора БД.
Второй недостаток связан с тем, что в процессе эксплуатации за счет некорректных удалений, сбоев и т.п. накапливается мусор – данные, к которым нет доступа. Часть этого мусора оказывается вовсе не мусором, а полезной, но утерянной информацией. Для восстановления целостности БД, а также для ее чистки, требуется кропотливая работа администратора.
Третий недостаток – слабая выразительность языка запросов. Обычно он позволяет манипулировать лишь одной записью одновременно, программист во время работы должен хорошо представлять себе пути доступа к данным.
Первая СУБД, построенная по сетевой модели – IDMS (1971 г.). Правами на нее обладает компания Computer Associates, она до сих пор поставляет и развивает эту СУБД. Примером может служить и СУБД IMAGE/1000 фирмы Hewlett-Packard.
Лекция 4 Пример базы данных, построенной на сетевой модели Постановка задачиБольшая организация имеет санатории разного профиля для выделения путевок в них своим сотрудникам (клиентам). Качество путевки определяется должностью клиента и учреждением, в котором он работает. Профиль санатория должен соответствовать профилю заболевания (определяется поликлиникой). В санатории могут быть места трех типов: палаты (коечный ресурс), люксы и комнаты. Они могут находиться в различных состояниях: свободны, заняты, броня, ремонт и т.п. Кроме сотрудников, клиентами могут быть их родственники и обслуживающий персонал санаторного управления. Последние получают путевки согласно выделенным талонам, которые могут иметь разный статус (выделен, выдан, аннулирован). В процессе формирования путевки она тоже может пребывать в разных статусах (предложена, выделена, напечатана, оплачена). Оплата путевки производится в соответствии со льготами, которые имеет данный клиент.
Требуется реализовать информационную систему, которая обеспечивает максимально бесконфликтное распределение мест в санаториях при условии возможного дефицита их в сезон массовых отпусков.
ДиаграммаФрагмент схемы БД, соответствующей приведенной постановке задачи, показан на диаграмме. Овалами обозначены владельцы, прямоугольниками – члены. Связи, естественно, направлены от владельцев к членам.
Особое место в диаграмме уделяется владельцу «Номер». Он связан со всеми членами, для которых характерно наличие номера в их определении, например, номер поликлиники, номер путевки, номер (код) родственного отношения. Такое решение позволило избавиться от многочисленных владельцев, представляющих собой номера (коды) сущностей, таких, как «Номер путевки», «Номер талона», «Код люкса» и т.п. Второй интересный набор – это «Вид льготы», не имеющий владельца. Это сингулярный набор, доступ к которому производится непосредственно через СУБД.
СУБДБаза данных реализована в сетевой СУБД IMAGE/1000 фирмы Hewlett-Packard. Устройство ее следующее. Общие сведения о базе данных хранятся в корневом файле. Наборы-владельцы (ключевые наборы), как и наборы-члены (детальные наборы) реализованы в виде отдельных файлов, структура которых различна.
Ключевые наборы представлены файлами постоянной длины, определяемой в момент генерации БД. По характеру доступа это перемешанные таблицы (хэш-таблицы). Доступ к записям производится по значению, которое представляется ключом соответствующей хэш-таблицы. Доступ к записям-членам производится по прямой ссылке на первую запись, соответствующую данному значению ключа.
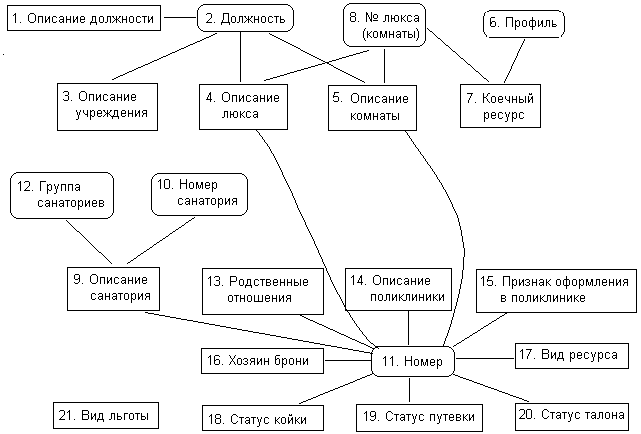
Диаграмма фрагмента БД «Санатории»
Детальные наборы представлены файлами произвольной длины. Их структура – совокупность линейных однонаправленных списков, каждый из которых соответствует одной записи-владельцу. Владелец ссылается на голову списка, остальные записи-члены выбираются по ссылочной цепочке. Каждая запись детального файла может участвовать в наборах, принадлежащих различным типам владельцев. Например, запись описания санатория может относиться к владельцу типа «Номер санатория» и к владельцу типа «Группа санаториев», но разным номерам санаториев не может соответствовать одна и та же запись описания.
В СУБД IMAGE/1000 реализован специальный ЯОД, подробное описание которого выходит за рамки курса. Приведенный фрагмент определения БД «Санатории» дает достаточное представление о характере этого языка. Пояснения приводятся в комментариях (ограничители комментариев – ).
$CONTROL: TABLE, ROOT, FIELD;
BEGIN DATA BASE: SANAT::29;
LEVELS:
1 INSP
10 MNGR
11 ADM
ITEMS:
NOM, X6(1,1);
NAME, X34(1,1);
NOMLK, I1(1,1);
OFFICE, X6(1,1);
OFFNAM, X34(1,1);
POST, X6(1,1);
POSTNAM, X34(1,1);
SANAT, X6(1,1);
SANAM, X34(1,1);
PROFIL, I1(1,1);
PRONAM, X34(1,1);
ADDRESS, X80;
WAY, X80;
NLUX, I1;
NROOM, I1;
NPAL, I1;
. . .
SETS:
NAME: NKPOS::29,A;
ENTRY:
POST(4),
CAPACITY: 817;
NAME: NOLXKO::29,A;
ENTRY:
NOM(4),
CAPACITY: 817;
. . .
NAME: NOLUX::29,D;
ENTRY:
NOM(NOLXKO),
NOMLK,
SANAT(NKLPOS),
NMEST,
CATEG(NKLMN),
QUALIT,
CAPACITY: 101;
Описание должности
NAME: NOPOST::29,D;
ENTRY:
POST(NOLXKO),
POSNAM,
CAPACITY: 311;
Вид льготы
NAME: NOLGO::29,D;
ENTRY:
NOMORD,
NAME,
CAPACITY: 7;
. . .
END.
23








Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!

