







© 2026, Ахматов Максим Сергеевич 29 1


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Был в сети 14.05.2026 08:24

Ахматов Максим Сергеевич
Преподаватель профессиональных дисциплин
Стратегии черного ящика. Эквивалентное разбиение. Анализ граничных значений
Категория:
Информатика
12.05.2026 14:32

Просмотр содержимого документа
«Стратегии черного ящика. Эквивалентное разбиение. Анализ граничных значений»

Стратегии черного ящика. Эквивалентное разбиение. Анализ граничных значений

Эквивалентное разбиение
Хороший тест имеет приемлемую вероятность обнаружения ошибки и что исчерпывающее входное тестирование программы невозможно. Следовательно, тестирование программы ограничивается использованием небольшого подмножества всех возможных входных данных. Тогда, конечно, хотелось бы выбрать для тестирования самое подходящее подмножество (т. е. подмножество с наивысшей вероятностью обнаружения большинства ошибок).

Правильно выбранный тест этого подмножества должен обладать двумя свойствами:
- уменьшать, причем более чем на единицу, число других тестов, которые должны быть разработаны для достижения заранее определенной цели «приемлемого» тестирования;
- покрывать значительную часть других возможных тестов, что в некоторой степени свидетельствует о наличии или отсутствии ошибок до и после применения этого ограниченного множества значений входных данных.

Указанные свойства, несмотря на их кажущееся подобие, описывают два различных положения.
- Во-первых, каждый тест должен включать столько различных входных условий, сколько это возможно, с тем, чтобы минимизировать общее число необходимых тестов.
- Во-вторых, необходимо пытаться разбить входную область программы на конечное число классов эквивалентности так, чтобы можно было предположить (конечно, не абсолютно уверенно), что каждый тест, являющийся представителем некоторого класса, эквивалентен любому другому тесту этого класса.

- Иными словами, если один тест класса эквивалентности обнаруживает ошибку, то следует ожидать, что и все другие тесты этого класса эквивалентности будут обнаруживать ту же самую ошибку. Наоборот, если тест не обнаруживает ошибки, то следует ожидать, что ни один тест этого класса эквивалентности не будет обнаруживать ошибки (в том случае, когда некоторое подмножество класса эквивалентности не попадает в пределы любого другого класса эквивалентности, так как классы эквивалентности могут пересекаться).

- Эти два положения составляют основу методологии тестирования по принципу черного ящика, известной как эквивалентное разбиение . Второе положение используется для разработки набора «интересных» условий, которые должны быть протестированы, а первое - для разработки минимального набора тестов, покрывающих эти условия.

- Примером класса эквивалентности для программы о треугольнике является набор «трех равных чисел, имеющих целые значения, большие нуля». Определяя этот набор как класс эквивалентности, устанавливают, что если ошибка не обнаружена некоторым тестом данного набора, то маловероятно, что она будет обнаружена другим тестом набора. Иными словами, в этом случае время тестирования лучше затратить на что-нибудь другое (на тестирование других классов эквивалентности).

- Разработка тестов методом эквивалентного разбиения осуществляется в два этапа:
- 1. выделение классов эквивалентности;
- 2. построение тестов.

Выделение классов эквивалентности
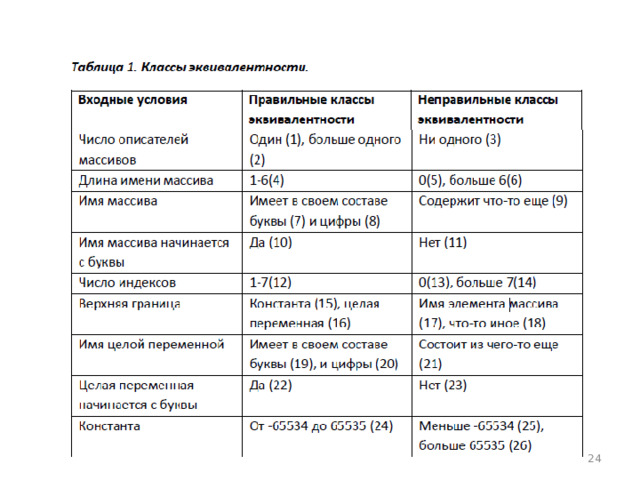
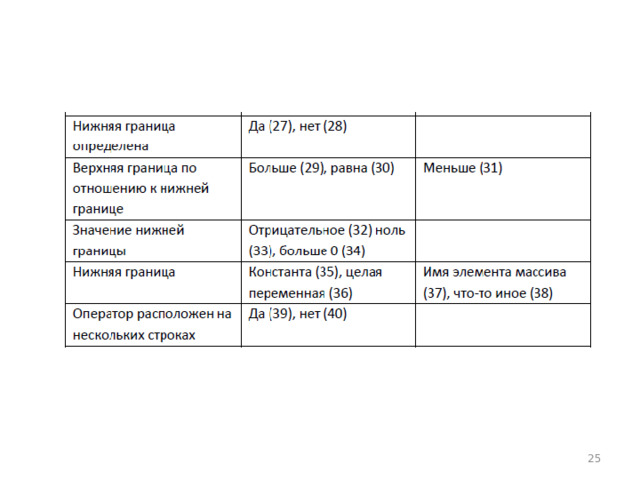
- Классы эквивалентности выделяются путем выбора каждого входного условия (обычно это предложение или фраза в спецификации) и разбиением его на две или более групп. Для проведения этой операции используют таблицу, изображенную на рис. 1.

- Заметим, что различают два типа классов эквивалентности: правильные классы эквивалентности, представляющие правильные входные данные программы, и неправильные классы эквивалентности, представляющие все другие возможные состояния условий (т. е. ошибочные входные значения). Таким образом, придерживаются одного из принципов тестирования о необходимости сосредоточивать внимание на неправильных или неожиданных условиях.

- Если задаться входными или внешними условиями, то выделение классов эквивалентности представляет собой в значительной степени эвристический процесс. При этом существует ряд правил:

- 1. Если входное условие описывает область значений (например, «целое данное может принимать значения от 1 до 99»), то определяются один правильный класс эквивалентности (1 99).
- 2. Если входное условие описывает число значений (например, «в автомобиле могут ехать от одного до шести человек»), то определяются один правильный класс эквивалентности и два неправильных (ни одного и более шести человек).
- 3. Если входное условие описывает множество входных значений и есть основание полагать, что каждое значение программа трактует особо (например, «известны должности ИНЖЕНЕР, ТЕХНИК, НАЧАЛЬНИК ЦЕХА, ДИРЕКТОР»), то определяется правильный класс эквивалентности для каждого значения и один неправильный класс эквивалентности (например, «БУХГАЛТЕР»).

- 4. Если входное условие описывает ситуацию «должно быть» (например, «первым символом идентификатора должна быть буква»), то определяется один правильный класс эквивалентности (первый символ - буква) и один неправильный (первый символ - не буква).
- 5. Если есть любое основание считать, что различные элементы класса эквивалентности трактуются программой неодинаково, то данный класс эквивалентности разбивается на меньшие классы эквивалентности.

Построение тестов
- Второй шаг заключается в использовании классов эквивалентности для построения тестов. Этот процесс включает в себя:
- 1. Назначение каждому классу эквивалентности уникального номера.
- 2. Проектирование новых тестов, каждый из которых покрывает как можно большее число непокрытых правильных классов эквивалентности, до тех пор, пока все правильные классы эквивалентности не будут покрыты (только не общими) тестами.

- 3. Запись тестов, каждый из которых покрывает один и только один из непокрытых неправильных классов эквивалентности, до тех пор, пока все неправильные классы эквивалентности не будут покрыты тестами. Причина покрытия неправильных классов эквивалентности индивидуальными тестами состоит в том, что определенные проверки с ошибочными входами скрывают или заменяют другие проверки с ошибочными входами. Например, спецификация устанавливает «тип книги при поиске (ВЫЧИСЛИТЕЛЬНАЯ ТЕХНИКА, ПРОГРАММИРОВАНИЕ или ОБЩИЙ) и количество (1-999)». Тогда тест XYZ 0 отображает два ошибочных условия (неправильный тип книги и количество) и, вероятно, не будет осуществлять проверку количества, так как программа может ответить: «XYZ - несуществующий тип книги» и не проверять остальную часть входных данных.

Пример
- Предположим, что при разработке интерпретатора для подмножества языка Бейсик требуется протестировать синтаксическую проверку оператора DIM. Спецификация приведена ниже. (Этот оператор не является полным оператором DIM Бейсика; спецификация была значительно сокращена, что позволило сделать ее «учебным примером». Не следует думать, что тестирование реальных программ так же легко, как в этом примере.) В спецификации элементы, написанные латинскими буквами, обозначают синтаксические единицы, которые в реальных операторах должны быть заменены соответствующими значениями, в квадратные скобки заключены необязательные элементы, многоточие показывает, что предшествующий ему элемент может быть повторен подряд несколько раз.
![Оператор DIM используется для определения массивов, форма оператора DIM: DIM ad[,ad]..., где ad есть описатель массива в форме n ( d [, d ]...),](https://static.multiurok.ru/multiurok/html/2026/05/12/s_6a030f9bf0cac/img16.jpg)
- Оператор DIM используется для определения массивов, форма оператора DIM:
- DIM ad[,ad]..., где ad есть описатель массива в форме
- n ( d [, d ]...),
![п - символическое имя массива, а d - индекс массива. Символические имена могут содержать от одного до шести символов - букв или цифр, причем первой должна быть буква. Допускается от одного до семи индексов. Форма индекса [lb : ] ub , где lb и ub задают нижнюю и верхнюю границы индекса массива.](https://static.multiurok.ru/multiurok/html/2026/05/12/s_6a030f9bf0cac/img17.jpg)
- п - символическое имя массива, а d - индекс массива. Символические имена могут содержать от одного до шести символов - букв или цифр, причем первой должна быть буква. Допускается от одного до семи индексов. Форма индекса
- [lb : ] ub , где lb и ub задают нижнюю и верхнюю границы индекса массива.

- Граница может быть либо константой, принимающей значения от -65534 до 65535, либо целой переменной (без индексов). Если lb не определена, то предполагается, что она равна единице. Значение ub должно быть больше или равно lb. Если lb определена, то она может иметь отрицательное, нулевое или положительное значение. Как и все операторы, оператор DIM может быть продолжен на нескольких строках. (Конец спецификации.)

- Первый шаг заключается в том, чтобы идентифицировать входные условия и по ним определить классы эквивалентности (табл. 1). Классы эквивалентности в таблице обозначены числами в круглых скобках.

- Следующий шаг - построение теста, покрывающего один или более правильных классов эквивалентности. Например, тест
- DIM A(2)
- покрывает классы 1, 4, 7, 10, 12, 15, 24, 28, 29 и 40 (см. табл. 1). Далее определяются один или более тестов, покрывающих оставшиеся правильные классы эквивалентности. Так, тест
- DIM A12345(I, 9, J4XXXX.65535, 1, KLM, X 100), ВВВ (-65534:100, 0:1000, 10:10, I:65535)
- покрывает оставшиеся классы.

- Перечислим неправильные классы эквивалентности и соответствующие им тесты:
- (3) DIM
- (5) DIM (10)
- (6) DIM A234567(2)
- (9) DIM A.1(2)
- (11) DIM 1A(10)
- (13) DIM В
- (14) DIM В (4,4,4,4,4,4,4,4)
- (17) DIM B(4,A(2))
- 21) DIM C(I.,10)
- (23) DIM c(10,1J)
- (25) DIM d(-65535:1)
- (26) DIM D (65536)
- (31) DIM D(4:3)
- (37) DIM d(a(2):4)
- (38) DIM d(.:4)

- Эти классы эквивалентности покрываются 18 тестами. Можно, при желании, сравнить данные тесты с набором тестов, полученным каким-либо специальным методом.
- Хотя эквивалентное разбиение значительно лучше случайного выбора тестов, оно все же имеет недостатки (т. е. пропускает определенные типы высокоэффективных тестов). Следующие два метода - анализ граничных значений и использование функциональных диаграмм (диаграмм причинно-следственных связей cause-effect graphing) - свободны от многих недостатков, присущих эквивалентному разбиению.

Анализ граничных значений
- Граничные условия - это ситуации, возникающие непосредственно выше или ниже границ входных и выходных классов эквивалентности.

- Анализ граничных значений отличается от эквивалентного разбиения в двух отношениях:
- 1. Выбор любого элемента в классе эквивалентности в качестве представительного при анализе граничных значений осуществляется таким образом, чтобы проверить тестом каждую границу этого класса.
- 2. При разработке тестов рассматривают не только входные условия (пространство входов), но и пространство результатов (т. е. выходные классы эквивалентности).

- Достаточно трудно описать принимаемые решения при анализе граничных значений, так как это требует определенной степени творчества и специализации в рассматриваемой проблеме. (Следовательно, анализ граничных значений, как и многие другие аспекты тестирования, в значительной мере основывается на способностях человеческого интеллекта.) Тем не менее существует несколько общих правил этого метода.

- 1. Построить тесты для границ области и тесты с неправильными входными данными для ситуаций незначительного выхода за границы области, если входное условие описывает область значений. Например, если правильная область входных значений есть от -1.0 до +1.0, то нужно написать тесты для ситуаций -1.0, 1.0, -1.001 и 1.001.
- 2. Построить тесты для минимального и максимального значений условий и тесты, большие и меньшие этих значений, если входное условие удовлетворяет дискретному ряду значений. Например, если входной файл может содержать от 1 до 255 записей, то получить тесты для 0, 1, 255 и 256 записей.

- 3. Использовать первое правило для каждого выходного условия. Например, если программа вычисляет ежемесячный расход и если минимум расхода составляет $0.00, а максимум - $1165.25, то построить тесты, которые вызывают расходы с $0.00 и $1165.25. Кроме того, построить, если это возможно, тесты, которые вызывают отрицательный расход и расход больше 1165.25 дол. Заметим, что важно проверить границы пространства результатов, поскольку не всегда границы входных областей представляют такой же набор условий, как и границы выходных областей (например, при рассмотрении подпрограммы вычисления синуса). Не всегда также можно получить результат вне выходной области, но тем не менее стоит рассмотреть эту возможность.

- 4. Использовать второе правило для каждого выходного условия. Например, если система информационного поиска отображает на экране наиболее релевантные статьи в зависимости от входного запроса, но никак не более четырех рефератов, то построить тесты, такие, чтобы программа отображала нуль, один и четыре реферата, и тест, который мог бы вызвать выполнение программы с ошибочным отображением пяти рефератов.

- 5. Если вход или выход программы есть упорядоченное множество (например, последовательный файл, линейный список, таблица), то сосредоточить внимание на первом и последнем элементах этого множества.
- 6. Попробовать свои силы в поиске других граничных условий.

- Чтобы проиллюстрировать необходимость анализа граничных значений, можно использовать программу анализа треугольника.
- Для задания треугольника входные значения должны быть целыми положительными числами, и сумма любых двух из них должна быть больше третьего.
 С, то программа ошибочно сообщала бы нам, что числа 1-2-3 представляют правильный равносторонний треугольник. " width="640"
С, то программа ошибочно сообщала бы нам, что числа 1-2-3 представляют правильный равносторонний треугольник. " width="640"
- Если определены эквивалентные разбиения, то целесообразно определить одно разбиение, в котором это условие выполняется, и другое, в котором сумма двух целых не больше третьего. Сле-довательно, двумя возможными тестами являются 3-4-5 и 1-2-4. Тем не менее, здесь есть вероятность пропуска ошибки. Иными словами, если выражение в программе было закодировано как А + В ≥ С вместо А + В С, то программа ошибочно сообщала бы нам, что числа 1-2-3 представляют правильный равносторонний треугольник.

- Таким образом, существенное различие между анализом граничных значений и эквивалентным разбиением заключается в том, что анализ граничных значений исследует ситуации, возникающие на и вблизи границ эквивалентных разбиений.

- В качестве примера применения метода анализа граничных значений рассмотрим следующую спецификацию программы.
- Пусть имеется программа или модуль, которая сортирует различную информацию об экзаменах. Входом программы является файл, названный results.txt, который содержит 80-символьные записи. Первая запись представляет название; ее содержание используется как заголовок каждого выходного отчета. Следующее множество записей описывает правильные ответы на экзамене. Каждая запись этого множества содержит «2» в качестве последнего символа. В первой записи в колонках 1-3 задается число ответов (оно принимает значения от 1 до 999). Колонки 10-59 включают сведения о правильных ответах на вопросы с номерами 1-50 (любой символ воспринимается как ответ). Последующие записи содержат в колонках 10-59 сведения о правильных ответах на вопросы с номерами 51-100, 101-150 и т. д. Третье множество записей описывает ответы каждого студента; любая запись этого набора имеет число «3» в восьмидесятой колонке. Для каждого студента первая запись в колонках 1-9 содержит его имя или номер (любые символы); в колонках 10-59 помещены сведения о результатах ответов студентов на вопросы с номерами 1-50. Если в тесте предусмотрено более чем 50 вопросов, то последующие записи для студента описывают ответы 51-100, 101-150 и т. д. в колонках 10-59. Максимальное число студентов - 200. Форматы входных записей показаны на рис. 2.

- Выходными записями являются:
- 1. отчет, упорядоченный в лексикографическом порядке идентификаторов студентов и показывающий качество ответов каждого студента (процент правильных ответов) и его ранг;

- 2. аналогичный отчет, но упорядоченный по качеству;
- 3. отчет, показывающий среднее значение, математическое ожидание (медиану) и дисперсию (среднеквадратическое отклонение) качества ответов;
- 4. отчет, упорядоченный по номерам вопросов и показывающий процент студентов, отвечающих правильно на каждый вопрос.


- Начнем методичное чтение спецификации, выявляя входные условия. Первое граничное входное условие есть пустой входной файл. Второе входное условие - карта (запись) названия; граничными условиями являются отсутствие карты названия, самое короткое и самое длинное названия. Следующими входными условиями служат наличие записей о правильных ответах и наличие поля числа вопросов в первой записи ответов. 1-999 не является классом эквивалентности для числа вопросов, так как для каждого подмножества из 50 записей может иметь место что- либо специфическое (т. е. необходимо много записей). Приемлемое разбиение вопросов на классы эквивалентности представляет разбиение на два подмножества: 1-50 и 51-999.

- Следовательно, необходимы тесты, где поле числа вопросов принимает значения 0, 1, 50, 51 и 999. Эти тесты покрывают большинство граничных условий для записей о правильных ответах; однако существуют три более интересные ситуации - отсутствие записей об ответах, наличие записей об ответах типа «много ответов на один вопрос» и наличие записей об ответах типа «мало ответов на один вопрос» (например, число вопросов - 50, и имеются три записи об ответах в первом случае и одна запись об ответах во втором). Таким образом, определены следующие тесты:

- 1. Пустой входной файл.
- 2. Отсутствует запись названия.
- 3. Название длиной в один символ.
- 4. Название длиной в 80 символов.
- 5. Экзамен из одного вопроса.
- 6. Экзамен из 50 вопросов.

- 7. Экзамен из 51 вопроса.
- 8. Экзамен из 999 вопросов.
- 9. 0 вопросов на экзамене.
- 10. Поле числа вопросов имеет нечисловые значения.
- 11. После записи названия нет записей о правильных ответах.
- 12. Имеются записи типа «много правильных ответов на один вопрос».
- 13. Имеются записи типа «мало правильных ответов на один вопрос».

- Следующие входные условия относятся к ответам студентов. Тестами граничных значений в этом случае, по-видимому, должны быть:
- 14. 0 студентов.
- 15. 1 студент.
- 16. 200 студентов.
- 17. 201 студент.
- 18. Есть одна запись об ответе студента, но существуют две записи о правильных ответах.
- 19. Запись об ответе вышеупомянутого студента первая в файле.
- 20. Запись об ответе вышеупомянутого студента последняя в файле.
- 21. Есть две записи об ответах студента, но существует только одна запись о правильном ответе.
- 22. Запись об ответах вышеупомянутого студента первая в файле.
- 23. Запись об ответах вышеупомянутого студента последняя в файле.

- Можно также получить набор тестов для проверки выходных границ, хотя некоторые из выходных границ (например, пустой отчет 1) покрываются приведенными тестами. Граничными условиями для отчетов 1 и 2 являются:
- 0 студентов (так же, как тест 14);
- 1 студент (так же, как тест 15);
- 200 студентов (так же, как тест 16).

- 24. Оценки качества ответов всех студентов одинаковы.
- 25. Оценки качества ответов всех студентов различны.
- 26. Оценки качества ответов некоторых, но не всех студентов одинаковы (для проверки правильности вычисления рангов).
- 27. Студент получает оценку качества ответа 0.
- 28. Студент получает оценку качества ответа 100.
- 29. Студент имеет идентификатор наименьшей возможной длины (для проверки правильности упорядочения).
- 30. Студент имеет идентификатор наибольшей возможной длины.
- 31. Число студентов таково, что отчет имеет размер, несколько больший одной страницы (для того чтобы посмотреть случай печати на другой странице).

- 32. Число студентов таково, что отчет располагается на одной странице.
- Граничные условия отчета 3 (среднее значение, медиана, среднеквадратическое отклонение).
- 33. Среднее значение максимально (качество ответов всех студентов наивысшее).
- 34. Среднее значение равно 0 (качество ответов всех студентов равно 0).
- 35. Среднеквадратическое отклонение равно своему максимуму (один студент получает оценку 0, а другой - 100).
- 36. Среднеквадратическое отклонение равно 0 (все студенты получают одну и ту же оценку).
- Тесты 33 и 34 покрывают и границы медианы. Другой полезный тест описывает ситуацию, где существует 0 студентов (проверка деления на 0 при вычислении математического ожидания), но он идентичен тесту 14.
- Проверка отчета 4 дает следующие тесты граничных значений:

- 37. Все студенты отвечают правильно на первый вопрос.
- 38. Все студенты неправильно отвечают на первый вопрос.
- 39. Все студенты правильно отвечают на последний вопрос.
- 40. Все студенты отвечают на последний вопрос неправильно.
- 41. Число вопросов таково, что размер отчета несколько больше одной страницы.
- 42. Число вопросов таково, что отчет располагается на одной странице.

- Опытный тестировщик, вероятно, согласится с той точкой зрения, что многие из этих 42 тестов позволяют выявить наличие общих ошибок, которые могут быть сделаны при разработке данной программы. Кроме того, большинство этих ошибок, вероятно, не было бы обнаружено, если бы использовался метод случайной генерации тестов или специальный метод генерации тестов. Анализ граничных значений, если он применен правильно, является одним из наиболее полезных методов проектирования тестов. Однако он часто оказывается неэффективным из-за того, что внешне выглядит простым. Необходимо понимать, что граничные условия могут быть едва уловимы и, следовательно, определение их связано с большими трудностями.
Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!

