
Россия, Нижний Новгород


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Был в сети 14.02.2024 11:45

Кликодуев Владимир Валерьевич
Учитель
46 лет
Местоположение
Специализация
Уроки Python 13 - Парсинг и Beautiful soup
Категория:
Информатика
31.12.2022 14:28

Просмотр содержимого документа
«Уроки Python 13 - Парсинг и Beautiful soup»
Уроки Python 13 - Парсинг и Beautiful soup
Очень часто возникает необходимость вытащить какую-то информацию с сайтов, в которых отсутствует API. Приходится применять технику, которая называется парсинг. Парсинг - это анализ исходного HTML кода веб-страницы и извлечение необходимых нам кусочков информации. Как получить HTML код любой веб-страницы с помощью requests.get(), было рассказано в предыдущем уроке. В данной статье, поговорим о парсинге.
Есть два пути вытаскивания нужных отрезков информации из HTML кода веб страниц
С использованием регулярных выражений
С использованием специальных модулей
Что такое регулярные выражения, мы разберем в следующих уроках. Скажу лишь, что применять регулярки для парсинга веб страниц нецелесообразно. Гораздо удобнее использовать готовые модули.
Рассмотрим один из таких модулей - Beautiful Soup. Он позволяет получать любые кусочки HTML кода и текста, делая выборку на основе указанных селекторов - классов или id искомых тегов. В этом он сильно похож на JQuery, если кто-то из вас занимается созданием сайтов, понять что такое селекторы не составит труда. Для остальных поясним:
Любая веб страница представляет из себя набор HTML тегов - специальных слов, которые заключены в скобки из значков больше-меньше. Например тег ссылки может выглядеть так
Ссылка
Мы можем получить любой тег, обратившись к нему по его классу, в данном случае '.n62' или по id - '#wn17'. В результате нам вернется тег с искомым id, либо список из тегов, у которых есть такой класс.
Чтобы распарсить какую-то веб страницу, нужно открыть её исходный код, найти в нём нужные нам теги, выписать их классы или id. А потом обращаться к ним по селекторам. Давайте поясним всё это на примере.
Сперва установим в Python модуль Beautiful Soup, дав в командной строке команду:
pip install beautifulsoup4
В программе мы должны будем вписать сокращенный вариант названия модуля
import bs4
Итак, для примера сделаем программу, которая получает прогноз погоды на сегодня по региону Москва. Информацию будем парсить вот отсюда:
https://sinoptik.com.ru/погода-москва
Сперва нам нужно понять, какие именно теги нам нужно вытаскивать.
Откроем HTML код страницы и найдём в нём показания температуры за утро и день. 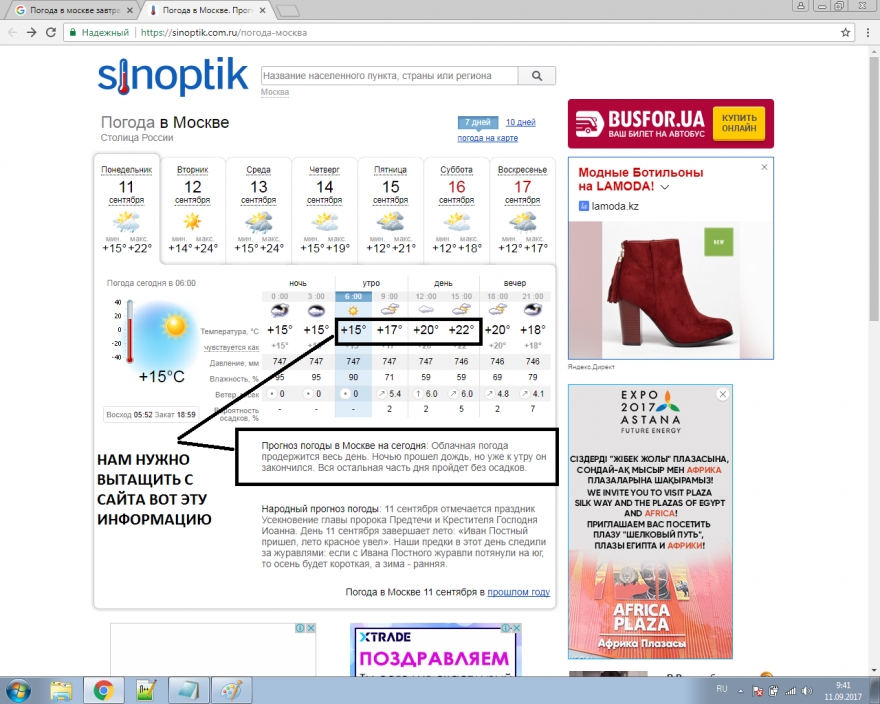
Мы заметим, что нужная нам температура расположена в тегах с классами p3, p4, p5, p6
В свою очередь, эти классы вложены в теги с классом temperatu
Значит селекторы для выборки этих тегов будут выглядеть так:
'.temperature .p3'
'.temperature .p4'
'.temperature .p5'
'.temperature .p6'
Теперь найдем в исходном коде тег где лежит текстовое описание погоды
Оно лежит в теге с классом description который вложен в тег с классом rSide. Значит селектор для получения этого тега будет таким:
'.rSide description'
Напишем программу:
import requests, bs4
s=requests.get('https://sinoptik.com.ru/погода-москва')
b=bs4.BeautifulSoup(s.text, "html.parser")
p3=b.select('.temperature .p3')
pogoda1=p3[0].getText()
p4=b.select('.temperature .p4')
pogoda2=p4[0].getText()
p5=b.select('.temperature .p5')
pogoda3=p5[0].getText()
p6=b.select('.temperature .p6')
pogoda4=p6[0].getText()
print('Утром :' + pogoda1 + ' ' + pogoda2)
print('Днём :' + pogoda3 + ' ' + pogoda4)
p=b.select('.rSide .description')
pogoda=p[0].getText()
print(pogoda.strip())
Итак, сперва мы получили в переменную s код веб страницы в виде HTML. Далее преобразовали этот код в объект для парсинга b=bs4.BeautifulSoup(s.text, "html.parser")
И теперь, используем select для получения нужных нам тегов. Команда select возвращает список из всех найденных тегов с заданным селектором. В нашем случае в возвращаемом списке всего 1 элемент с индексом 0, потому что мы ищем не повторяющиеся значения тегов. Например, чтобы получить первое значение температуры, сперва получим список всех найденных совпадений p3=b.select('.temperature .p3') а уже потом возьмем текст из нулевого элемента полученного списка pogoda1=p3[0].getText()
С остальными тегами всё точно также. Мы просто задаём селектор, состоящий из имён классов искомых тегов, получаем список найденных тегов, и берем с этого списка нулевой элемент(нумерация списков идёт с нуля).
Полученные переменные мы выводим с помощью print И получаем что-то вроде этого: 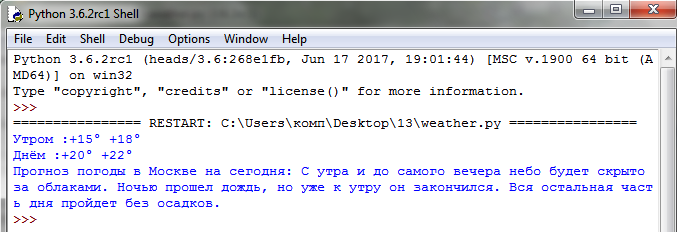
Вы можете изменить в программе город на ваш, поменяв в конце адреса s=requests.get('https://sinoptik.com.ru/погода-москва') название города. Подобным образом можно получить информацию не только с сайта погоды, а вообще с ЛЮБОГО сайта.








Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!

