

СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока


Анализ ручного ввода ответа

Просмотр содержимого документа
«Анализ ручного ввода ответа»
АНАЛИЗ РУЧНОГО ВВОДА ОТВЕТА В ТЕСТАХ
В.В. Карасиков
Во время тестирования учащихся на компьютере, при ручном вводе ответа, мы сталкиваемся с двумя основными проблемами: ввод синонимов и появление в тексте опечаток или ошибок. Будем говорить, что если ответ дан верно, то ему соответствует значение 1, если не верно, то 0, если в тексте появляется ошибка, то значение будет между 0 и 1.
Рассмотрим первую проблему (есть несколько вариантов правильного ответа). Например, был задан вопрос: «Какого цвета эта красная сумочка?». В зависимости от логики рассуждения тестируемого он может дать следующие ответы: «Красного» (ответ на вопрос какого); «Красная» (сумочка); «Красный» (цвет). Не теряя общности, все эти ответы мы можем считать правильными. Возможность вводить несколько правильных вариантов ответа реализована в программе TestReader 5.01. Пример вопроса с несколькими вариантами верных ответов в программе показан на рисунке 1.
?Какого цвета эта красная сумочка
* красного
* красная
* красный
{
}
Рис.1. Пример вопроса с ручным вводом ответа и с несколькими вариантами правильного ответа
Следующая проблема - появление в тексте опечаток или ошибок. Для решения этой задачи выполним следующие шаги:
Шаг 1. «Склеиваем слова» - убираем символы «пробел» в веденном тексте и тексте правильного ответа, убираем регистр букв.
Шаг 2. Строим массивы действительных чисел, ставим в соответствие каждому символу число. Символы на шкале располагаем в порядке частоты ошибки (чем чаще эти символы путают, тем ближе они друг к другу). Также можно ввести «Символы-синонимы», т.е. символы, которым в соответствие ставится одно и тоже число (Например: «Е» и «Ё»). Таким образом, получаем следующую таблицу:
Таблица 1
Таблица подстановки
| Символ: | А | Я | О | Ё | Е | Э | Й | И | Ы | У | Ю |
| Значение: | 0,1 | 0,15 | 0,20 | 0,25 | 0,30 | 0,35 | 0,40 | 0,45 | 0,50 | 0,70 | 0,75 |
| С-вол: | Б | П | В | Ф | Г | К | Х | Д | Т | Ж | З | С | Ц | Л | М | Н | Р | Ч | Ш | Щ | Ъ | Ь |
| Знач.: | 2,10 | 2,15 | 2,20 | 2,25 | 2,50 | 2,55 | 2,60 | 2,80 | 2,85 | 3,00 | 3,20 | 3,25 | 3,30 | 3,80 | 4,00 | 4,05 | 5,00 | 5,50 | 6,00 | 6,05 | 7,00 | 7,05 |
| Символ: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 |
| Значение: | 50 | 55 | 60 | 65 | 70 | 75 | 80 | 85 | 90 | 95 |
Для прочих символов соответствующее число вычисляется по формуле: 
Где х - значение кода символа в таблице ASCII, y - число в таблице подстановки. Например, для символа «.» (точка) 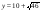 =16.78, а для символа «,» (запятая)
=16.78, а для символа «,» (запятая)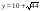 = 16,63
= 16,63
Шаг 3. Если длины строк совпадают, то переходим к шагу 4, иначе:
3.1. Находим наибольшее общее кратное длин строк.(НОК)
3.2. Масштабируем каждый массив данных до длины НОК.
Шаг 4. Рассматриваем массив данных, как корреляционный процесс. Проверяем полученные массивы чисел на взаимосвязь. Вычисляем коэффициент корреляции по формуле:
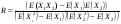
Где X1 и X2 – массивы чисел соответствующие пользовательскому и правильному ответам, E – среднее арифметическое массива чисел.
Если R
Шаг 5. Вычисляем штраф за ошибку (Результирующею функцию).
Для вычисления результирующей оценки корреляцион-ного анализа недостаточно. Предлагается следующая формула:
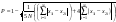
Где x1i и x2i – i-ый символ в пользовательском и правильном ответах соответственно.
Приведем два примера:
1. Сравним ошибку для слов: «Плоток» «Плиток» и «Плитка» при условии, что правильный ответ «Платок».
R(плоток, платок) = 0,999754440.6;
R(плиток, платок) = 0,9744360.6;
R(плитка, платок) = 0,456937 принимаем решение, что ошибок слишком много, следовательно P=0;
P(плоток, платок)= 0,870901 – незначительная опечатка;
P(плиток, платок)= 0,612702 – серьезная опечатка;
2. Сравним слова «пласмасс» (пропущенна «т») и «пластмасс».
НОК(8,9)=72. Масштабируем оба массива до 72-х значений.
R(пласмасс, пластмасс)= 0,7413590.6
P(пласмасс, пластмасс)= 0,615689
Вывод: данный метод позволяет свести к минимуму влияние опечаток и безграмотности пользователей там, где это необходимо. Алгоритм применен в программе TestReader 5.01.
Литература:
1. Корн Г., Корн Т. Справочник по математика для научных работников и инженеров/под общ.ред. И.Г. Араманович – M: «Наука», 1974, – 832 с.
2. Сидоренко Е.В. Методы математической обработки. - СПб.: СПбГУ, 2006. – 367 с.








Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!

