Россия, Иваново


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Была в сети 20.12.2022 13:21
Реукова Ирина Германовна
Учитель математики
63 года
Местоположение
Специализация
Исследовательский метод. Проекты.
Категория:
Математика
19.12.2018 22:14

Просмотр содержимого документа
«Исследовательский метод. Проекты.»

Вероятность и окружающие предметы

Почему на клавиатуре компьютера буквы расположены не в порядке алфавита?

Гипотеза.
Часто встречающиеся буквы расположены на самых удобных местах клавиатуры, встречающиеся редко – на менее удобных.

Как подтвердить или опровергнуть эту гипотезу?
Провести исследование!!!

Программа исследования.
- Мы взяли страницу текста на русском языке.
- Вычислили частоту встречаемости различных букв в тексте.

Метод.
Мы использовали формулу для вычисления вероятности случайного события .

Формула.
- P (A) - вероятность случайного события A ( от англ. probability – «вероятность» )
- A – выбранная наугад буква алфавита (например, буква «а»)
- N - количество типографических знаков в тексте
- N (A) – количество выбранных букв в тексте (букв «а»)

Исследование.
Что выбрать в качестве объекта исследования?..

… Учебник?
Нецелесообразно использовать в качестве объекта, так как здесь много специальных терминов.

… Модный журнал?
Нецелесообразно, сленговый язык не подходит для проводимого исследования.
… Письма друзей в Контакте?
Нецелесообразно, слишком много орфографических и грамматических ошибок…

Объектом нашего исследования стал текст классического произведения «Мастер и Маргарита».

Ход исследования.
Возьмём страницу текста. Подсчитаем вероятность для буквы «о» :
- N = 56*38=2128
- N(O) =19 2
- P(O) =19 2 /2128=0,090
Устойчивая частота появления буквы «о»
0,090

Получение и обработка данных.
- Маша
вычисляла
частоту
гласных
букв в тексте.

- Ваня, Артём,
Андрей
подсчитывали
частоту
согласных
букв.

- Ваня, Артём,
Андрей
подсчитывали
частоту
согласных
букв.

- Иван считал
частоту знаков
и пробелов.
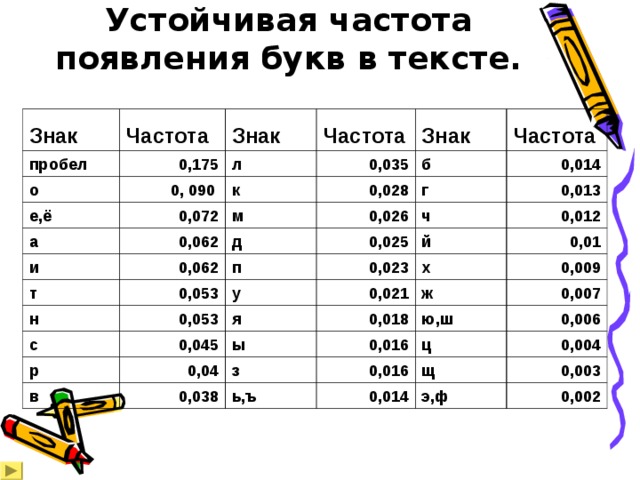
Устойчивая частота появления букв в тексте.
Знак
Частота
пробел
0,175
Знак
о
е,ё
0, 090
л
Частота
0,035
0,072
Знак
а
к
0,028
0,062
Частота
б
м
и
0,014
0,026
0,062
д
г
т
0,025
н
0,053
ч
п
0,013
0,053
0,023
0,012
с
у
й
я
0,01
0,021
х
0,045
р
0,009
0,04
0,018
в
ы
ж
з
0,038
0,016
ю,ш
0,007
0,006
0,016
ц
ь,ъ
0,004
щ
0,014
0,003
э,ф
0,002
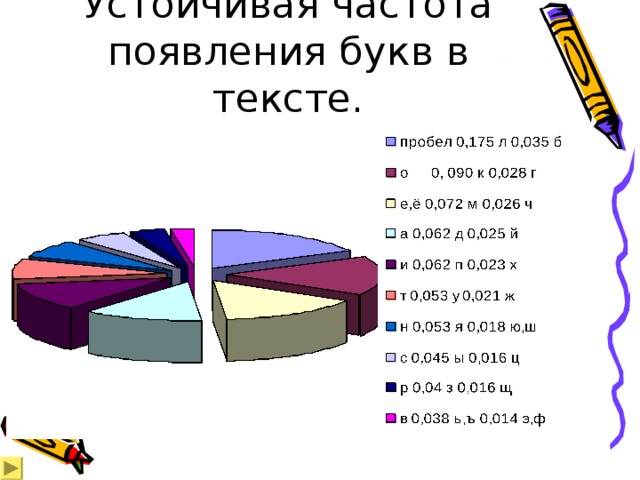
Устойчивая частота появления букв в тексте.

Результаты исследования.
- Вероятность того, что наугад выбранная буква алфавита окажется, например, буквой «а», примерно равна 0,062 , а вероятность того, что мы таким же случайным способом выберем букву «э», равна всего 0,002 .
- Самая часто встречающаяся буква алфавита – «о».
- Самые редко встречающиеся буквы в тексте - буквы «э» и «ф».
- Гласные буквы встречаются чаще согласных.
- Чаще всего в тексте встречается пробел.

Вывод.
Буквы с наиболее высокой устойчивой частотой появления в тексте («о», «е», «а», «и», «т», «н») находятся в центре клавиатуры.
«Под рукой»!

Зона ближайшего исследования.
В языке можно обнаружить и другие вероятностные закономерности. Эти закономерности изучает специальная наука – математическая лингвистика.
Можно так же определить наиболее часто встречающиеся слоги («на», «по»).
А наиболее часто встречающееся слово?...

Раскрываем секреты истории.

- Первыми обнаружили устойчивость частоты появления букв в тексте арабские учёные ( I тыс. н.э.).
- Они использовали это для чтения зашифрованных сообщений.
- Для хранения и передачи секретных текстов использовались шифры замены.

Метод шифровки.
- Чтобы зашифровать сообщение, каждая буква исходного текста заменялась какой-нибудь другой буквой (символом).
- Одинаковые буквы заменялись одинаковыми символами (разные - разными).

Метод дешифровки.
- Предложен арабским учёным Аль-Кинди в IX в. н.э.
- Основан на частотных свойствах букв.

Для чтения шифрованных текстов необходимо:
- Для каждого символа шифрованного текста посчитать его частоту.
- Расположить символы в порядке убывания частоты.
- Буквы алфавита данного языка расположить в порядке убывания частоты.
- Заменить символы текста буквами алфавита так: 1-й символ 1-ой буквой, 2-й символ – 2-й буквой и т.д.

Это изобретение очень сильно упростило работу по расшифровке и заставило создателей шифров искать новые пути…

Исследование провели учащиеся 9-го класса.








Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!

