








© 2021, Годунов Никита Борисович 603 0


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока
Регулярные выражения
Категория:
Информатика
24.09.2021 00:52

Просмотр содержимого документа
«Регулярные выражения»
Пространство имен RegularExpression и классы регулярных выражений
Стандартный класс String позволяет выполнять над строками различные операции, в том числе поиск, замену, вставку и удаление подстрок. Существуют специальные операции, такие как Join, Split, которые облегчают разбор строки на элементы. Тем не менее, есть классы задач по обработке символьной информации, где стандартных возможностей явно не хватает. Чтобы облегчить решение подобных задач, в Net Framework встроен более мощный аппарат работы со строками, основанный на регулярных выражениях.
Специальное пространство имен RegularExpression, содержит набор классов, обеспечивающих работу с регулярными выражениями. Все классы этого пространства доступны для C# и всех языков, использующих каркас Net Framework. В основе регулярных выражений лежит хорошая теория и хорошая практика их применения. Полное описание, как теоретических основ, так и практических особенностей применения этого аппарата в C#, требует отдельной книги. Придется ограничиться введением в эту интересную область работы со строками, не рассматривая подробно все классы, входящие в пространство имен RegularExpression.
Пусть T = {a1, a2, an} - алфавит символов. Словом в алфавите T называется
последовательность записанных подряд символов, а длиной слова - число его символов. Пустое слово, не содержащее символов, обычно обозначается как e. Алфавит T можно рассматривать как множество всех слов длины 1. Рассмотрим операцию конкатенации над множествами, так, что конкатенация алфавита T с самим собой дает множество всех слов длины 2. Обозначается конкатенация ТТ как Т2. Множество всех слов длины k обозначается - Tk, его можно рассматривать как k-кратную конкатенацию алфавита T. Множество всех непустых слов произвольной длины, полученное объединением всех множеств Tk, обозначается T+, а объединение этого множества с пустым словом называется итерацией языка и обозначается T*. Итерация описывает все возможные слова, которые можно построить в данном алфавите. Любое подмножество слов L(T), содержащееся в T*, называется языком в алфавите T.
Определим класс языков, задаваемых регулярными множествами. Регулярное множество
определяется рекурсивно следующими правилами:
пустое множество, а также множество, содержащее пустое слово, и одноэлементные множества, содержащие символы алфавита, являются регулярными базисными множествами;
если множества P и Q являются регулярными, то множества, построенные применением операций объединения, конкатенации и итерации - PQ, PQ, P*, Q* - тоже являются регулярными.
Регулярные выражения представляют удобный способ задания регулярных множеств.
Аналогично множествам, они определяются рекурсивно:
регулярные базисные выражения задаются символами и определяют соответствующие регулярные базисные множества, например, выражение f задает одноэлементное множество {f} при условии, что f - символ алфавита T;
если p и q - регулярные выражения, то операции объединения, конкатенации и итерации - p+q, pq, p*, q* - являются регулярными выражениями, определяющими соответствующие регулярные множества.
По сути, регулярные выражения - это более простой и удобный способ записи регулярных множеств в виде обычной строки. Каждое регулярное множество, а, следовательно, и каждое регулярное выражение задает некоторый язык L(T) в алфавите T. Этот класс
языков - достаточно мощный, с его помощью можно описать интересные языки, но устроены они довольно просто - их можно определить также с помощью простых грамматик, например, правосторонних грамматик. Более важно, что для любого регулярного выражения можно построить конечный автомат, который распознает, принадлежит ли заданное слово языку, порожденному регулярным выражением. На этом основана практическая ценность регулярных выражений.
С точки зрения практика регулярное выражение задает образец поиска. После чего можно проверить, удовлетворяет ли заданная строка или ее подстрока данному образцу. В языках программирования синтаксис регулярного выражения существенно обогащается, что дает возможность более просто задавать сложные образцы поиска. Такие синтаксические надстройки, хотя и не меняют сути регулярных выражений, крайне полезны для практиков, избавляя программиста от ненужных сложностей. (В Net Framework эти усложнения, на мой взгляд, чрезмерны. Выигрывая в мощности языка, проигрываем в простоте записи его выражений.)
Регулярное выражение на C# задается строковой константой. Это может быть обычная или @-константа. Чаще всего, следует использовать именно @-константу. Дело в том, что символ "\" широко применяется в регулярных выражениях как для записи escape- последовательностей, так и в других ситуациях. Обычные константы в таких случаях будут выдавать синтаксическую ошибку, а @-константы не выдают ошибок и корректно интерпретируют запись регулярного выражения.
Синтаксис регулярного выражения простой формулой не описать, здесь используются набор разнообразных средств:
символы и escape-последовательности;
символы операций и символы, обозначающие специальные классы множеств;
имена групп и обратные ссылки;
символы утверждений и другие средства.
Конечно, регулярное выражение может быть совсем простым, например, строка "abc" задает образец поиска, так что при вызове соответствующего метода будут разыскиваться одно или все вхождения подстроки "abc" в искомую строку. Но могут существовать и очень сложно устроенные регулярные выражения. Приведу таблицу, (15.1) в которой дается интерпретация символов в соответствии с их делением на группы. Таблица не полна, в ней отражаются не все группы, а описание группы не содержит всех символов. Она позволяет дать общее представление о синтаксисе, которое будет дополнено большим числом примеров. За деталями придется обращаться к справочной системе, которая, к сожалению, далеко не идеальна для данного раздела.
Повторяю, данная таблица не полна. В ней не отражены, например, такие категории, как подстановки, обратные ссылки, утверждения.
Для приведенных категорий также не дан полный список возможных символов.
Таблица 15.1. Символы, используемые в регулярных выражениях
| Символ | Интерпретация |
|
| Категория: escape-последовательности |
| \b | При использовании его в квадратных скобках соответствует имволу "обратная косая черта" с кодом - \u0008 |
| \t | Соответствует символу табуляции \u0009 |
| \r | Соответствует символу возврата каретки \u000D |
| \n | Соответствует символу новой строки \u000A |
| \e | Соответствует символу escape \u001B |
| \040 | Соответствует символу ASCII, заданному кодом до трех цифр в восьмеричной системе |
| \x20 | Соответствует символу ASCII, заданному кодом из двух цифр в шестнадцатиричной системе |
| \u0020 | Соответствует символу Unicode, заданному кодом из четырех цифр в шестнадцатиричной системе |
|
| Категория: подмножества (классы) символов |
| . | Соответствует любому символу, за исключением символа конца строки |
| [aeiou] | Соответствует любому символу из множества, заданного в квадратных скобках |
| [^aeiou] | Отрицание. Соответствует любому символу, за исключением символов, заданных в квадратных скобках |
| [0-9a-fA- F] | Задание диапазона символов, упорядоченных по коду. Так, 0-9 задает любую цифру |
| \p{name} | Соответствует любому символу, заданному множеству с именем name, например, имя Ll задает множество букв латиницы в нижнем регистре. Поскольку все символы разбиты на подмножества, задаваемые категорией Unicode, то в качестве имени можно задавать имя категории |
| \P{name} | Отрицание. Большая буква всегда задает отрицание множества, заданного малой буквой |
| \w | Множество символов, используемых при задании идентификаторов - большие и малые символы латиницы, цифры и знак подчеркивания |
| \s | Соответствует символам белого пробела |
| \d | Соответствует любому символу из множества цифр |
|
| Категория: Операции (модификаторы) |
| * | Итерация. Задает ноль или более соответствий; например, \w* или |
| (abc)*. | Аналогично, {0,} |
| + | Положительная итерация. Задает одно или более соответствий; например, \w+ или (abc)+. Аналогично, {1,} |
| ? | Задает ноль или одно соответствие; например, \w? или (abc)?. Аналогично, {0,1} |
| {n} | Задает в точности n соответствий; например, \w{2} |
| {n,} | Задает, по меньшей мере, n соответствий; например, (abc){2,} |
| {n,m} | Задает, по меньшей мере, n, но не более m соответствий; например, (abc){2,5} |
|
| Категория: Группирование |
| (?) | При обнаружении соответствия выражению, заданному в круглых скобках, создается именованная группа, которой дается имя Name. Например, (? \d{7}). При обнаружении последовательности из семи цифр будет создана группа с именем tel |
| () | Круглые скобки разбивают регулярное выражение на группы. Для каждого подвыражения, заключенного в круглые скобки, создается группа, автоматически получающая номер. Номера следуют в обратном порядке, поэтому полному регулярному выражению соответствует группа с номером 0 |
| (?imnsx) | Включает или выключает в группе любую из пяти возможных опций. Для выключения опции перед ней ставится знак минус. Например, (?i-s: ) включает опцию i, задающую нечувствительность к регистру, и выключает опцию s - статус single-line |
В данном пространстве расположено семейство из одного перечисления и восьми связанных между собой классов.
Это основной класс, всегда создаваемый при работе с регулярными выражениями. Объекты этого класса определяют регулярные выражения. Конструктор класса, как обычно, перегружен. В простейшем варианте ему передается в качестве параметра строка, задающая регулярное выражение. В других вариантах конструктора ему может быть передан объект, принадлежащий перечислению RegexOptions и задающий опции, которые действуют при работе с данным объектом. Среди опций отмечу одну: ту, что позволяет компилировать регулярное выражение. В этом случае создается программа, которая и будет выполняться при каждом поиске соответствия. При разборе больших текстов скорость работы в этом случае существенно повышается.
Рассмотрим четыре основных метода класса Regex.
Метод Match запускает поиск соответствия. В качестве параметра методу передается строка поиска, где разыскивается первая подстрока, которая удовлетворяет образцу, заданному регулярным выражением.В качестве результата метод возвращает объект класса Match, описывающий результат поиска. При успешном поиске свойства объекта будут содержать информацию о найденной подстроке.
Метод Matches позволяет разыскать все вхождения, то есть все подстроки, удовлетворяющие образцу. У алгоритма поиска есть важная особенность - разыскиваются непересекающиеся вхождения подстрок. Можно считать, что метод Matches многократно запускает метод Match, каждый раз начиная поиск с того места, на котором закончился предыдущий поиск. В качестве результата возвращается объект MatchCollection, представляющий коллекцию объектов Match.
Метод NextMatch запускает новый поиск, начиная с того места, на котором остановился предыдущий поиск.
Метод Split является обобщением метода Split класса String. Он позволяет, используя образец, разделить искомую строку на элементы. Поскольку образец может быть устроен сложнее, чем простое множество разделителей, то метод Split класса Regex эффективнее, чем его аналог класса String.
Как уже говорилось, объекты этих классов создаются автоматически при вызове методов Match и Matches. Коллекция MatchCollection, как и все коллекции, позволяет получить доступ к каждому ее элементу - объекту Match. Можно, конечно, организовать цикл for each для последовательного доступа ко всем элементам коллекции.
Класс Match является непосредственным наследником класса Group, который, в свою очередь, является наследником класса Capture. При работе с объектами класса Match наибольший интерес представляют не столько методы класса, сколько его свойства, большая часть которых унаследована от родительских классов. Рассмотрим основные свойства:
свойства Index, Length и Value наследованы от прародителя Capture. Они описывают найденную подстроку- индекс начала подстроки в искомой строке, длину подстроки и ее значение;
свойство Groups класса Match возвращает коллекцию групп - объект GroupCollection, который позволяет работать с группами, созданными в процессе поиска соответствия;
свойство Captures, наследованное от объекта Group, возвращает коллекцию
CaptureCollection. Как видите, при работе с регулярными выражениями реально
приходится создавать один объект класса Regex, объекты других классов автоматически появляются в процессе работы с объектами Regex.
Коллекция GroupCollection возвращается при вызове свойства Group объекта Match. Имея эту коллекцию, можно добраться до каждого объекта Group, в нее входящего. Класс Group является наследником класса Capture и, одновременно, родителем класса Match. От своего родителя он наследует свойства Index, Length и Value, которые и передает своему потомку.
Давайте рассмотрим чуть более подробно, когда и как создаются группы в процессе поиска соответствия. Если внимательно проанализировать предыдущую таблицу, которая описывает символы, используемые в регулярных выражениях, в частности символы группирования, то можно понять несколько важных фактов, связанных с группами:
при обнаружении одной подстроки, удовлетворяющей условию поиска, создается не одна группа, а коллекция групп;
группа с индексом 0 содержит информацию о найденном соответствии;
число групп в коллекции зависит от числа круглых скобок в записи регулярного выражения. Каждая пара круглых скобок создает дополнительную группу, которая описывает ту часть подстроки, которая соответствует шаблону, заданному в круглых скобках;
группы могут быть индексированы, но могут быть и именованными, поскольку в круглых скобках разрешается указывать имя группы.
В заключение отмечу, что создание именованных групп крайне полезно при разборе строк, содержащих разнородную информацию. Примеры разбора подобных текстов будут даны.
Коллекция CaptureCollection возвращается при вызове свойства Captures объектов класса Group и Match. Класс Match наследует это свойство у своего родителя - класса Group. Каждый объект Capture, входящий в коллекцию, характеризует соответствие, захваченное в процессе поиска, - соответствующую подстроку. Но поскольку свойства объекта Capture передаются по наследству его потомкам, то можно избежать непосредственной работы с объектами Capture. По крайней мере, в моих примерах не встретится работа с этим объектом, хотя "за кулисами" он непременно присутствует.
Объекты этого перечисления описывают опции, влияющие на то, как устанавливается соответствие. Обычно такой объект создается первым и передается конструктору объекта класса Regex. В вышеприведенной таблице, в разделе, посвященном символам группирования, говорится о том, что опции можно включать и выключать, распространяя, тем самым, их действие на участок шаблона, заданный соответствующей группой. Об одной из этих опций - Compiled, влияющей на эффективность работы регулярных выражений, уже упоминалось. Об остальных говорить не буду - при необходимости можно посмотреть справку.
При работе со сложными и большими текстами полезно предварительно скомпилировать используемые в процессе поиска регулярные выражения. В этом случае необходимо будет создать объект класса RegexCompilationInfo и передать ему информацию о регулярных выражениях, подлежащих компиляции, и о том, куда поместить оттранслированную программу. Дополнительно в таких ситуациях следует включить опцию Compiled. К сожалению, соответствующих примеров на эту тему не будет.
Примеры работы с регулярными выражениями
Полагаю, что примеры дополнят краткое описание возможностей регулярных выражений и позволят лучше понять, как с ними работать. Начну с функции FindMatch, которая производит поиск первого вхождения подстроки, соответствующей образцу:
string FindMatch(string str, string strpat)
{
Regex pat = new Regex(strpat); Match match =pat.Match(str); string found = "";
if (match.Success)
{
found =match.Value;
Console.WriteLine("Строка ={0}\tОбразец={1}\ tНайдено={2}", str,strpat,found);
}
return(found);
}//FindMatch
В качестве входных аргументов функции передается строка str, в которой ищется вхождение, и строка patstr, задающая образец - регулярное выражение. Функция возвращает найденную в результате поиска подстроку. Если соответствия нет, то возвращается пустая строка. Функция начинает свою работу с создания объекта pat класса Regex, конструктору которого передается образец поиска. Затем вызывается метод Match этого объекта, создающий объект match класса Match. Далее анализируются свойства этого объекта. Если соответствие обнаружено, то найденная подстрока возвращается в качестве результата, а соответствующая информация выводится на печать. (Чтобы спокойно работать с классами регулярных выражений, я не забыл добавить в начало проекта предложение: using System.Text.RegularExpressions.)
Поскольку запись регулярных выражений - вещь, привычная не для всех программистов, я приведу достаточно много примеров:
public void TestSinglePat()
{
//поиск по образцу первого вхождения string str,strpat,found; Console.WriteLine("Поиск по образцу");
//образец задает подстроку, начинающуюся с символа a,
//далее идут буквы или цифры. str ="start"; strpat =@"a\w+"; found = FindMatch(str,strpat); str ="fab77cd efg";
found = FindMatch(str,strpat);
//образец задает подстроку,начинающуюся с символа a,
//заканчивающуюся f с возможными символами b и d в середине
strpat = "a(b|d)*f"; str = "fabadddbdf"; found = FindMatch(str,strpat);
//диапазоны и escape-символы strpat = "[X-Z]+"; str = "aXYb"; found = FindMatch(str,strpat);
strpat = @"\u0058Y\x5A"; str = "aXYZb"; found = FindMatch(str,strpat);
}//TestSinglePat
Некоторые комментарии к этой процедуре.
Регулярные выражения задаются @-константами, описанными в лекции 14. Здесь они как нельзя кстати.
В первом образце используется последовательность символов \w+, обозначающая, как следует из таблицы 15.1, непустую последовательность латиницы и цифр. В совокупности
образец задает подстроку, начинающуюся символом a, за которым следуют буквы или цифры (хотя бы одна). Этот образец применяется к двум различным строкам.
В следующем образце используется символ * для обозначения итерации. В целом регулярное выражение задает строки, начинающиеся с символа a и заканчивающиеся символом f, между которыми находится возможно пустая последовательность символов из b и d.
Последующие два образца демонстрируют использование диапазонов и escape- последовательностей для представления символов, заданных кодами (в Unicode и шестнадцатиричной кодировке).
Взгляните на результаты, полученные при работе этой процедуры.

Рис. 15.1. Регулярные выражения. Поиск по образцу
Не всякий класс языков можно описать с помощью регулярных выражений. И даже тогда, когда такая возможность есть, могут потребоваться определенные усилия для корректной записи соответствующего регулярного выражения. Рассмотрим, например, язык L1 в алфавите T={0,1}, которому принадлежат пустое слово и слова, содержащие четное число нулей и четное число единиц. В качестве другого примера рассмотрим язык L2, отличающийся от первого тем, что в нем число единиц нечетно. Оба языка можно задать регулярными выражениями, но корректная запись непроста и требует определенного навыка. Давайте запишем регулярные выражения, определяющие эти языки, и покажем, что C# справляется с проблемой их распознавания. Вот регулярное выражение, описывающее первый язык:
(00|11)*((01|10)(00|11)*(01|10)(00|11)*)*
Дадим содержательное описание этого языка. Слова языка представляют возможно пустую последовательность из пар одинаковых символов. Далее может идти последовательность, начинающаяся и заканчивающаяся парами различающихся символов, между которыми может стоять произвольное число пар одинаковых символов. Такая группа может повторяться многократно. Регулярное выражение короче и точнее передает описываемую структуру слов языка L1.
Язык L2 описать теперь совсем просто. Его слова представляют собой единицу, окаймленную словами языка L1.
Прежде чем перейти к примеру распознавания слов языков L1 и L2, приведу процедуру
FindMatches, позволяющую найти все вхождения образца в заданный текст:
void FindMatches(string str, string strpat)
{
Regex pat = new Regex(strpat); MatchCollection matchcol =pat.Matches(str);
Console.WriteLine("Строка ={0}\tОбразец={1}",str,strpat); Console.WriteLine("Число совпадений ={0}",matchcol.Count); foreach(Match match in matchcol)
Console.WriteLine("Index = {0} Value = {1}, Length ={2}", match.Index,match.Value, match.Length);
}//FindMatches
Входные аргументы у процедуры те же, что и у функции FindMatch, ищущей первое вхождение. Я не стал задавать выходных аргументов процедуры, ограничившись тем, что все результаты непосредственно выводятся на печать в самой процедуре. Выполнение процедуры, так же, как и в FindMatch, начинается с создания объекта pat класса Regex, конструктору которого передается регулярное выражение. Замечу, что класс Regex, так же, как и класс String, относится к неизменяемым (immutable) классам, поэтому для каждого нового образца нужно создавать новый объект pat.
В отличие от FindMatch, объект pat вызывает метод Matches, который определяет все вхождения подстрок, удовлетворяющих образцу, в заданный текст. Результатом выполнения метода Matches является автоматически создаваемый объект класса MatchCollection, хранящий коллекцию объектов уже известного нам класса Match, каждый из которых задает очередное вхождение. В процедуре используются свойства коллекции и ее элементов для получения в цикле по элементам коллекции нужных свойств - индекса очередного вхождения подстроки в строку, ее длины и значения.
Вот процедура, в которой многократно вызывается FindMatches для различных строк и образцов поиска:
public void TestMultiPat()
{
//поиск по образцу всех вхождений
string str,strpat,found; Console.WriteLine("Распознавание языков: чет и нечет");
//четное число нулей и единиц
strpat ="((00|11)*((01|10)(00|11)*(01|10)(00|11)*)*)"; str = "0110111101101";
FindMatches(str, strpat);
//четное число нулей и нечетное единиц string strodd = strpat + "1" + strpat; FindMatches(str, strodd);
}//TestMultiPat
Коротко прокомментирую работу этой процедуры. Первые два примера связаны с распознаванием языков L1 и L2 (чет и нечет) - языков с четным числом единиц и нулей в первом случае и нечетным числом единиц во втором. Регулярные выражения, описывающие эти языки, подробно рассматривались. В полном соответствии с теорией, константы задают эти выражения. На вход для распознавания подается строка из нулей и единиц. Для языка L1 метод находит три соответствия. Первое из них задает максимально длинную подстроку, содержащую четное число нулей и единиц, и две пустые подстроки, по определению принадлежащие языку L1. Для языка L2 находится одно соответствие - это сама входная строка. Взгляните на результаты распознавания.
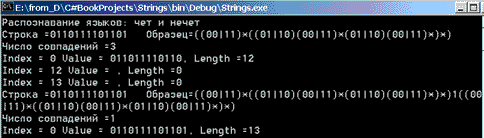
Рис. 15.2. Регулярные выражения. Пример "чет и нечет"
Следующий образец в нашем примере позволяет прояснить некоторые особенности работы метода Matches. Сколько раз строка "око" входит в строку "рококо" - один или два? Все зависит от того, как считать. С точки зрения метода Matches, - один раз, поскольку он разыскивает непересекающиеся вхождения, начиная очередной поиск вхождения подстроки с того места, где закончилось предыдущее вхождение. Еще один пример на эту же тему работает с числовыми строками.
Console.WriteLine("око и рококо"); strpat="око"; str = "рококо"; FindMatches(str, strpat); strpat="123";
str= "0123451236123781239";
FindMatches(str, strpat);
На рис. 15.3 показаны результаты поисков.
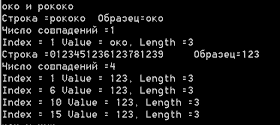
Рис. 15.3. Регулярные выражения. Пример "око и рококо"
Этот пример на поиск множественных соответствий навеян словами песни Высоцкого, где говорится, что дикари не смогли распознать, где кок, а где Кук. Наше регулярное выражение также не распознает эти слова. Обратите внимание на точку в регулярном выражении, которая соответствует любому символу, за исключением символа конца строки. Все слова в строке поиска - кок, кук, кот и другие - будут удовлетворять шаблону, так что в результате поиска найдется множество соответствий.
Console.WriteLine("кок и кук"); strpat="(т|к).(т|к)";
str="кок тот кук тут как кот"; FindMatches(str, strpat);
Вот результаты работы этого фрагмента кода.

Рис. 15.4. Регулярные выражения. Пример "кок и кук"
В этом примере рассматривается ранее упоминавшаяся, но не описанная возможность задания в регулярном выражении обратных ссылок. Можно ли описать с помощью регулярных выражений язык, в котором встречаются две подряд идущие одинаковые подстроки? Ответ на это вопрос отрицательный, поскольку грамматика такого языка должна быть контекстно-зависимой, и нужна память, чтобы хранить уже распознанные части строки. Аппарат регулярных выражений, предоставляемый классами пространства RegularExpression, тем не менее, позволяет решить эту задачу. Причина в том, что расширение стандартных регулярных выражений в Net Framework является не только синтаксическим. Содержательные расширения связаны с введением понятия группы, которой отводится память и дается имя. Это и дает возможность ссылаться на уже созданные группы, что и делает грамматику языка контекстно-зависимой. Ссылка на ранее полученную группу называется обратной ссылкой. Признаком обратной ссылки является пара символов "\k", после которой идет имя группы. Приведу пример:
Console.WriteLine("Ссылка назад - второе вхождение слова"); strpat = @"\s(?\w+)\s\k'word'";
str = "I know know that, You know that!"; FindMatches(str, strpat);
Рассмотрим более подробно регулярное выражение, заданное строкой strpat. В группе, заданной скобочным выражением, после знака вопроса идет имя группы "word", взятое в угловые скобки. После имени группы идет шаблон, описывающий данную группу, в нашем примере шаблон задается произвольным идентификатором "\w+"(? так? кто кого задает?). В дальнейшем описании шаблона задается ссылка на группу с именем "word". Здесь имя группы заключено в одинарные кавычки. Поиск успешно справился с поставленной задачей, подтверждением чему являются результаты работы этого фрагмента кода.

Рис. 15.5. Регулярные выражения. Пример "обратные ссылки"
Давайте вернемся к задаче разбора предложения на элементы. В классе string для этого имеется метод Split, который и решает поставленную задачу. Однако у этого метода есть существенный недостаток, - он не справляется с идущими подряд разделителями и создает для таких пар пустые слова. Метод Split класса Regex лишен этих недостатков, в качестве разделителей можно задавать любую пару символов, произвольное число пробелов и другие комбинации символов. Повторим наш прежний пример:
public void TestParsing()
{
string str,strpat;
//разбор предложения - создание массива слов
str = "А это пшеница, которая в темном чулане хранится," +" в доме, который построил Джек!";
strpat =" +|, ";
Regex pat = new Regex(strpat); string[] words;
words = pat.Split(str); int i=1;
foreach(string word in words) Console.WriteLine("{0}: {1}",i++,word);
}//TestParsing
Регулярное выражение, заданное строкой strpat, определяет множество разделителей. Заметьте, в качестве разделителя задан пробел, повторенный сколь угодно много раз, либо пара символов - запятая и пробел. Разделители задаются регулярными выражениями.
Метод Split применяется к объекту pat класса Regex. В качестве аргумента методу передается текст, подлежащий расщеплению. Вот как выглядит массив слов после применения метода Split.

Рис. 15.6. Регулярные выражения. Пример "Дом Джека"
Как уже говорилось, регулярные выражения особенно хороши при разборе сложных текстов. Примерами таковых могут быть различные справочники, различные текстовые базы данных, весьма популярные теперь XML-документы, разбором которых приходится заниматься. В качестве заключительного примера рассмотрим структурированный документ, строки которого содержат некоторые атрибуты, например, телефон, адрес и e- mail. Структуру документа можно задавать по-разному; будем предполагать, что каждый атрибут задается парой "имя: Значение" Наша задача состоит в том, чтобы выделить из строки соответствующие атрибуты. В таких ситуациях регулярное выражение удобно задавать в виде групп, где каждая группа соответствует одному атрибуту. Приведу начальный фрагмент кода очередной тестирующей процедуры, в котором описываются строки текста и образцы поиска:
public void TestAttributes()
{
string s1 = "tel: (831-2) 94-20-55 ";
string s2 = "Адрес: 117926, Москва, 5-й Донской проезд, стр.10,кв.7";
string s3 = "e-mail: Valentin.Berestov@tverorg.ru "; string s4 = s1+ s2 + s3;
string s5 = s2 + s1 + s3;
string pat1 = @"tel:\s(?\((\d|-)*\)\s(\d|-)+)\s"; string pat2= @"Адрес:\s(?[0-9А-Яа-я \-\,\.]+)\s"; string pat3 =@"e-mail:\s(?[a-zA-Z.@]+)\s";
string compat = pat1+pat2+pat3; string tel="", addr = "", em = "";
Строки s4 и s5 представляют строку разбираемого документа. Их две, для того чтобы можно было проводить эксперименты, когда атрибуты в документе представлены в произвольном порядке. Каждая из строк pat1, pat2, pat3 задает одну именованную группу в регулярном выражении, имена групп - tel, Адрес, e-mail - даются в соответствии со смыслом атрибутов. Сами шаблоны подробно описывать не буду - сделаю лишь одно замечание. Например, шаблон телефона исходит из того, что номеру предшествует код, заключенный в круглые скобки. Поскольку сами скобки играют особую роль, то для задания скобки как символа используется пара - "\(". Это же касается и многих других символов, используемых в шаблонах, - точки, дефиса и т.п. Строка compat представляет составное регулярное выражение, содержащее все три группы. Строки tel, addr и em нам понадобятся для размещения в них результатов разбора. Применим вначале к строкам s4 и s5 каждый из шаблонов pat1, pat2, pat3 в отдельности и выделим соответствующий атрибут из строки. Вот код, выполняющий эти операции:
Regex reg1 = new Regex(pat1);
Match match1= reg1.Match(s4); Console.WriteLine("Value =" + match1.Value); tel= match1.Groups["tel"].Value; Console.WriteLine(tel);
Regex reg2 = new Regex(pat2);
Match match2= reg2.Match(s5); Console.WriteLine("Value =" + match2.Value); addr= match2.Groups["addr"].Value; Console.WriteLine(addr);
Regex reg3 = new Regex(pat3); Match match3= reg3.Match(s5);
Console.WriteLine("Value =" + match3.Value); em= match3.Groups["em"].Value; Console.WriteLine(em);
Все выполняется нужным образом - создаются именованные группы, к ним можно получить доступ и извлечь найденный значения атрибутов. А теперь попробуем решить ту же задачу одним махом, используя составной шаблон compat:
Regex comreg = new Regex(compat);
Match commatch= comreg.Match(s4); tel= commatch.Groups["tel"].Value; Console.WriteLine(tel);
addr= commatch.Groups["addr"].Value; Console.WriteLine(addr);
em= commatch.Groups["em"].Value; Console.WriteLine(em);
}// TestAttributes
 И эта задача успешно решается. Взгляните на результаты разбора текста.
И эта задача успешно решается. Взгляните на результаты разбора текста.
Рис. 15.7. Регулярные выражения. Пример "Атрибуты"
На этом и завершим рассмотрение регулярных выражений а также лекции, посвященные работе с текстами в C#.
Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!

